Segmentação no cMIPS
© Roberto André Hexsel, 2014-2017 O objetivo deste laboratório é avaliar sua compreensão dos conceitos de segmentação, adiantamento, branch delay-slots e load delay-slots. Para tanto você deverá se familiarizar com o simulador do MIPS e então acompanhar a simulação de quatro programas em assembly no processador segmentado, e alterá-los para tirar proveito dos circuitos de adiantamento do processador, ou para preencher os delay-slots com instruções úteis.Antes de mais nada, crie um prompt vazio, copiando a linha abaixo no seu terminal alias prompt:="" Três clicks no botão esquerdo para copiar, um click no meio para colar. Este prompt lhe ajudará a copiar comandos direto desta página.
Sobre os diretórios de simulação O simulador deve ser executado no diretório ~/cmips/cMIPS Os testes devem ser executados no diretório ~/cmips/cMIPS/tests Os programas de testes devem ser compilados no diretório ~/cmips/cMIPS/tests e os "executáveis" prog.bin e data.bin devem ser movidos para ~/cmips/cMIPS Sobre a variável de ambiente PATH A variável PATH deve ser aumentada com o caminho dos scripts necessários para as simulações. Se, por acaso ou acidente, você fechar a Shell em que executava as simulações, o caminho para os scripts deve novamente ser acrescentado à PATH.
0- Faça a clonagem do repositório
Para copiar o código fonte do simulador para sua área, execute prompt: cd ; git clone https://github.com/rhexsel/cmips.git e ignore as mensagens sobre certificados que não são confiáveis. Mantenha o simulador instalado porque ele será necessário para o trabalho desta disciplina. Toda a vez em que uma nova versão for copiada do github, aqueles arquivos do repositório que foram atualizados (ou corrigidos) no repositório serão atualizados no seu clone. ACHTUNG: Se você alterar arquivo(s) em sua cópia local, suas atualizações poderão ser sobrescritas pela versão do repositório.1- Teste sua cópia
Acrescente o diretório dos executáveis do cMIPS ao seu caminho: prompt: export PATH=$PATH:~/cmips/cMIPS/bin Construa o simulador: prompt: cd ~/cmips/cMIPS prompt: build.sh O script build.sh compila o código VHDL do simulador. Este script deve executar por uns 10 segundos, e pode produzir a saída de um diff, caso alguma configuração de endereço seja automagicamente efetuada. Em geral, o script só produz uma lista de arquivos VHDL compilados, a menos que ocorra algum erro. Neste caso, informe ao professor. O executável do simulador do cMIPS se chama tb_cmips. Execute os programas de teste para garantir que o simulador está correto: prompt: cd tests prompt: ./doTests.sh Uma lista de nomes é impressa na tela. Executar os testes toma de 1 a 3 minutos, dependendo da capacidade do seu computador. O script imprime uma longa lista com os nomes dos arquivos de teste, na medida em que são executados. Se os testes não produziram nenhuma mensagem de erro, sua instalação está em ordem. Do contrário, informe ao professor.2- Monte um arquivo em assembly
Ainda no diretório de testes, montemos um programa em assembly. Vejamos o código fonte de sltbeq.s. Os números das linhas não fazem parte do programa fonte.1 .include "cMIPS.s" 2 .text 3 .align 2 4 .set noat 5 .globl _start 6 .ent _start 7 _start: la $15,(x_IO_BASE_ADDR+0x10) 8 addi $9,$0,6 9 addi $3,$0,1 10 move $4,$zero 11 nop 12 snd: add $4,$4,$3 # $4 + 1 $4 <- 1,2,3,4,5,6 13 sw $4, -16($15) 14 nop 15 slt $1,$4,$9 16 bne $0,$1,snd 17 nop 18 nop 19 nop 20 nop 21 wait 22 .end _start
O que há em cada linha do código fonte? 1: inclui arquivo com as definições dos endereços 2: início da seção com código (.text) 3: endereços devem ser alinhados em endereços múltiplos de 4=2**2 4: não usar o registrador $at 5: _start é um símbolo visível fora deste arquivo 6: ponto de entrada do código neste arquivo (primeira instrução por executar) 7: carrega em $15 o endereço da área de E/S, para facilitar a depuração 13: escreve o valor de $4 na área de E/S (endereços altos) 15: instrução sob teste 16: instrução sob teste 17-20: esvazia os segmentos do processador 21: a instrução wait termina a simulação 21: final do código de _start. Os quatro NOPs nas linhas 17 a 20 servem para "esvaziar" o processador simulado, antes que esse decodifique a instrução wait da linha 21. Essa instrução interrompe a simulação no instante em que é decodificada, e sem os 4 NOPs, a simulação seria interrompida cedo demais, possivelmente produzindo resultados incompletos. Assim, os 4 NOPs são um artefato da simulação, e não do processador. Vejamos a saída do montador, cujo resultado é mostrado e comentado. prompt: assemble.sh -v sltbeq.s A saída com -v (verbosa) mostra o programa montado.
sltbeq.elf: file format elf32-littlemips Disassembly of section .text: 00000000 <_start>: 0: 3c0f0f00 lui $15,0xf00 4: 35ef0010 ori $15,$15,0x10 8: 20090006 addi $9,$0,6 c: 20030001 addi $3,$0,1 10: 00002021 move $4,$0 14: 00000000 nop 00000018
Este programa executa no processador sem nenhuma infraestrutura que não esteja no próprio código, e neste exemplo há somente uma seção .text. O que é exibido é a desmontagem do resultado da montagem e ligação, que é o conteúdo do arquivo intermediário chamado sltbeq.elf. As quatro colunas são, a partir da margem esquerda: endereço da instrução, a instrução, seu equivalente em assembly, e comentários (não há neste exemplo). O código inicia no endereço zero, e termina no endereço 0x40. O NOP do endereço 0x2c foi introduzido pelo montador para preencher o branch delay-slot do desvio no endereço 0x28. Os endereços e a instrução são codificados em hexadecimal e serão muito úteis no acompanhamento das simulações com o GTKWAVE. A montagem e a compilação para o cMIPS produzem os arquivos prog.bin e data.bin, com o código a ser armazenado na ROM, e os dados que são armazenados na RAM, caso seu programa contenha variáveis inicializadas (nada em data.bin neste exemplo). Para que este programa possa ser simulado, prog.bin e o data.bin devem ser copiados para o diretório acima de tests: prompt: assemble.sh -v sltbeq.s && mv prog.bin data.bin .. && cd ..
3- Simulação sem visualização
De volta ao diretório cMIPS, executemos a simulação: prompt: run.sh Este script constrói o simulador e executa a simulação com base nos arquivos prog.bin e data.bin. No caso do sltbeq.s a saída é:elaborate tb_cmips 00000001 00000002 00000003 00000004 00000005 00000006 core.vhd:775:7:@1175ns:(assertion failure): cMIPS BREAKPOINT at PC=00000040 opc=010000 fun=100000 brk=10000000000000000000 SIMULATION ENDED (correctly?) AT exit(); /home/roberto/cMIPS/tb_cmips:error: assertion failed /home/roberto/cMIPS/tb_cmips:error: simulation failed
No endereço x_IO_BASE_ADDR fica o periférico print, e qualquer escrita neste endereço é enviada para a saída padrão do simulador e exibida em hexadecimal, com 8 dígitos. A primeira linha da saída é o resultado da compilação do modelo VHDL e indica que o modelo foi compilado corretamente. O programa sltbeq.s escreve seis inteiros na saída padrão do simulador e então encerra a simulação, ao executar o wait do endereço 0x40, linha 21 no código fonte. As cinco linhas após os números são produzidas pelo simulador, e não pela execução do programa sltbeq.s. A primeira indica o tempo simulado de execução (indicado em vermelho); a segunda e a terceira indicam o endereço e opcode da instrução que causou o término do programa, no wait do endereço 0x40. O brk indica a condição que causou o término do programa, e neste caso a condição é zero (ignore o 1 à esquerda); a condição é mostrada nos 5 bits menos significativos. As duas últimas linhas são geradas por GHDL e não sei como nos livrar delas.
4- Simulação com visualização
Faço uso do arquivo ~/.gtkwaverc para a configuração do gtkwave, que desabilita a tela inicial e escolhe o tamanho das letras, permitindo a exibição de (quase) todos os sinais na tela. O conteúdo do meu ~/.gtkwaverc é mostrado abaixo. Talvez nem todos os corpos e tamanhos de letra estejam disponíveis no seu sistema. O tipo fixed existe em todos os sistemas que conheço.initial_window_x -1 left_justify_sigs 1 enable_fast_exit 1 splash_disable 1 vcd_preserve_glitches 1 fontname_signals fixed 9 fontname_waves fixed 7 # fontname_waves terminus 7
Para invocar o gtkwave deve-se passar o argumento '-w' para run.sh. Pode-se escolher o arquivo com a configuração do gtkwave. Para tanto use a opção -v: prompt: run.sh -w -v pipe_min.sav & O programa é simulado e o gtkwave é então iniciado em background. O pipe_min.sav configura o gtkwave para exibir um mínimo de sinais, que são aqueles mostrados nos dois diagramas do processador.
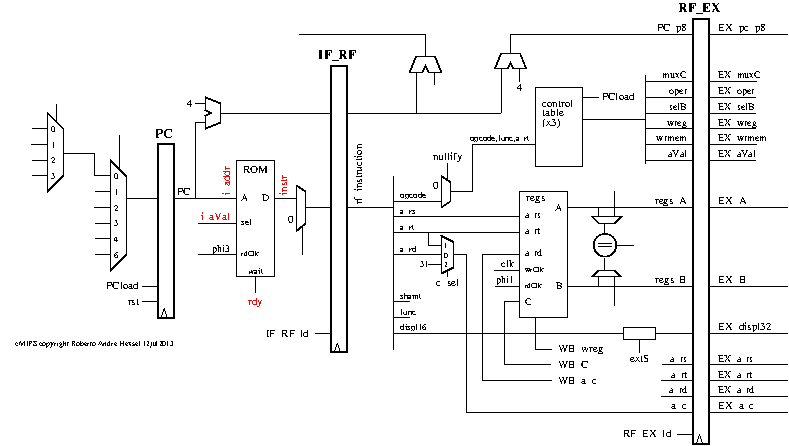 Os sinais do cMIPS mostrados na tela do gtkwave são agrupados por
estágio do pipeline, e de cima para baixo são Busca (FETCH),
Decodificação (DEC) Execução (EXEC), Memória (MEM), e Resultado
(WR BACK). A figura abaixo mostra o diagrama de tempos com os
agrupamentos de sinais indicados pelos retângulos coloridos.
Os sinais do cMIPS mostrados na tela do gtkwave são agrupados por
estágio do pipeline, e de cima para baixo são Busca (FETCH),
Decodificação (DEC) Execução (EXEC), Memória (MEM), e Resultado
(WR BACK). A figura abaixo mostra o diagrama de tempos com os
agrupamentos de sinais indicados pelos retângulos coloridos.
 O arquivo docs/cMIPS.pdf contem diagramas com os nomes de (quase)
todos os sinais do processador, de forma que é possível acompanhar a
execução das instruções pelos sinais mostrados no diagrama de tempo.
Agora a parte complicada: uma instrução é mostrada no diagrama de tempo
como se estivesse descendo uma escada. No ciclo C, ela está na busca;
em C+1 na decodificação e desceu um degrau; no ciclo C+2 na execução e um
degrau abaixo; no ciclo C+3 na memória, e no ciclo C+4 no write-back que é
o último degrau.
Olhando o diagrama durante um ciclo que é uma fatia vertical
do diagrama de tempos, o que vemos são cinco instruções distintas, uma em
cada fase de execução.
Olhando o diagrama ao longo de uma fatia horizontal, o que vemos são
várias instruções num mesmo estágio.
Para seguir a execução de uma instrução, devemos seguir uma
fatia diagonal do diagrama.
O diagrama de tempos mostrado acima é ligeiramente diferente daquele que
você obtém ao simular o sltbeq.s, porque a figura foi obtida da
execução de outro programa.
Observe agora o seu diagrama da execução do sltbeq.s. No ciclo em
300ns ocorre um acesso ao periférico, que é a instrução sw no endereço
0x0000.001c. Endereços na faixa de 0x00xx.0000 a 0x00xx.ffff (x!=0) são
para referências à RAM enquanto que na faixa 0x0f000xxx são para acessar os
periféricos.
Siga a execução do programa sltbeq, acompanhando a execução com
a saída do montador: observe o endereço da instrução (no PC) e confirme seu
opcode no estágio de decodificação; depois siga a execução até o final
daquela instrução.
Altere o programa, para usar uma instrução beq, ao invés
de bne, na linha 16. Re-monte o programa e verifique os resultados.
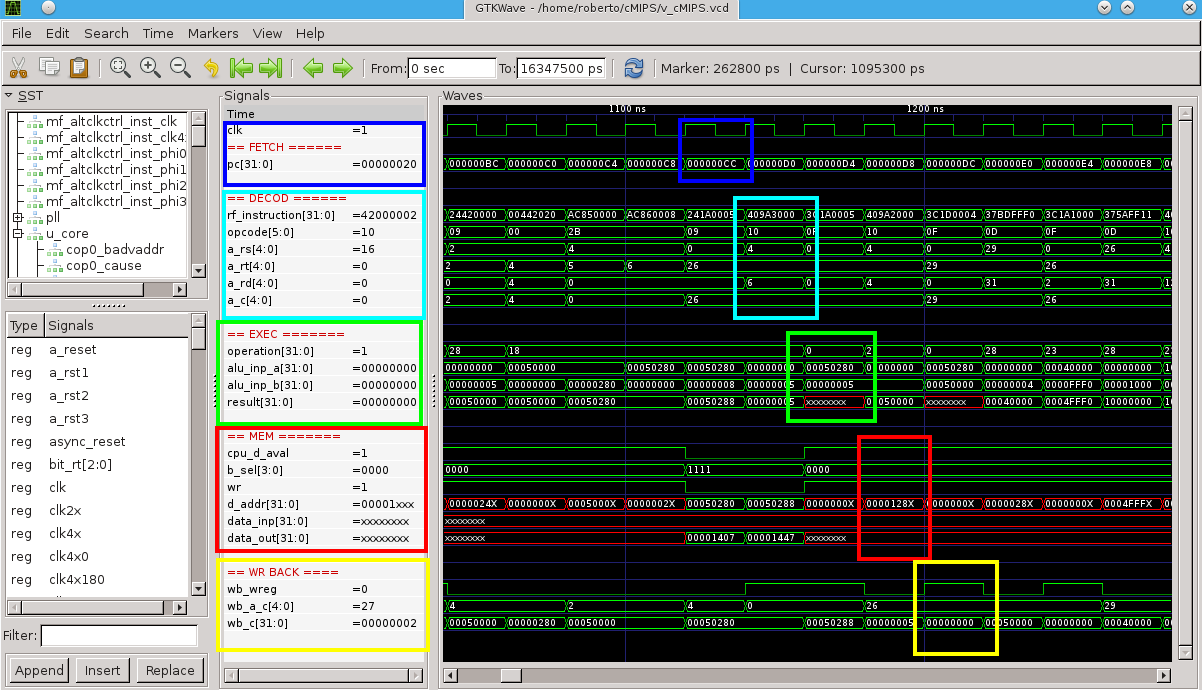
O arquivo docs/cMIPS.pdf contem diagramas com os nomes de (quase)
todos os sinais do processador, de forma que é possível acompanhar a
execução das instruções pelos sinais mostrados no diagrama de tempo.
Agora a parte complicada: uma instrução é mostrada no diagrama de tempo
como se estivesse descendo uma escada. No ciclo C, ela está na busca;
em C+1 na decodificação e desceu um degrau; no ciclo C+2 na execução e um
degrau abaixo; no ciclo C+3 na memória, e no ciclo C+4 no write-back que é
o último degrau.
Olhando o diagrama durante um ciclo que é uma fatia vertical
do diagrama de tempos, o que vemos são cinco instruções distintas, uma em
cada fase de execução.
Olhando o diagrama ao longo de uma fatia horizontal, o que vemos são
várias instruções num mesmo estágio.
Para seguir a execução de uma instrução, devemos seguir uma
fatia diagonal do diagrama.
O diagrama de tempos mostrado acima é ligeiramente diferente daquele que
você obtém ao simular o sltbeq.s, porque a figura foi obtida da
execução de outro programa.
Observe agora o seu diagrama da execução do sltbeq.s. No ciclo em
300ns ocorre um acesso ao periférico, que é a instrução sw no endereço
0x0000.001c. Endereços na faixa de 0x00xx.0000 a 0x00xx.ffff (x!=0) são
para referências à RAM enquanto que na faixa 0x0f000xxx são para acessar os
periféricos.
Siga a execução do programa sltbeq, acompanhando a execução com
a saída do montador: observe o endereço da instrução (no PC) e confirme seu
opcode no estágio de decodificação; depois siga a execução até o final
daquela instrução.
Altere o programa, para usar uma instrução beq, ao invés
de bne, na linha 16. Re-monte o programa e verifique os resultados.
5- Adiantamento
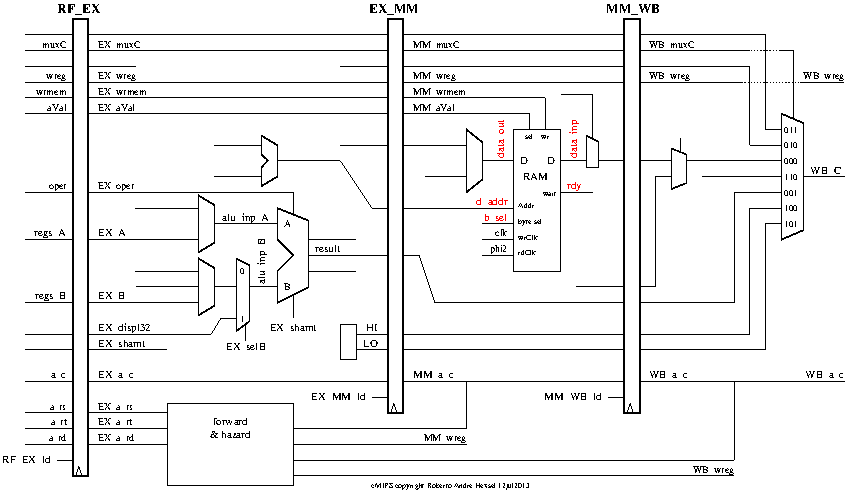
Para examinarmos o processador com adiantamento usaremos um arquivo de configuração do gtkwave que mostra os sinais de entrada dos circuitos de adiantamento. Para tanto encerre o gtkwave e o reinicie com outro arquivo de configuração: prompt: run.sh -w -v pipe_Med.sav & O diagrama de tempos mostra os sinais de entrada dos multiplexadores de adiantamento do estágio de execução (forward into {A,B}) e do estágio de memória (forward to mem). Antes de prosseguir, encontre os sinais mostrados no gtkwave no diagrama de blocos completo do processador, em docs/cMIPS.pdf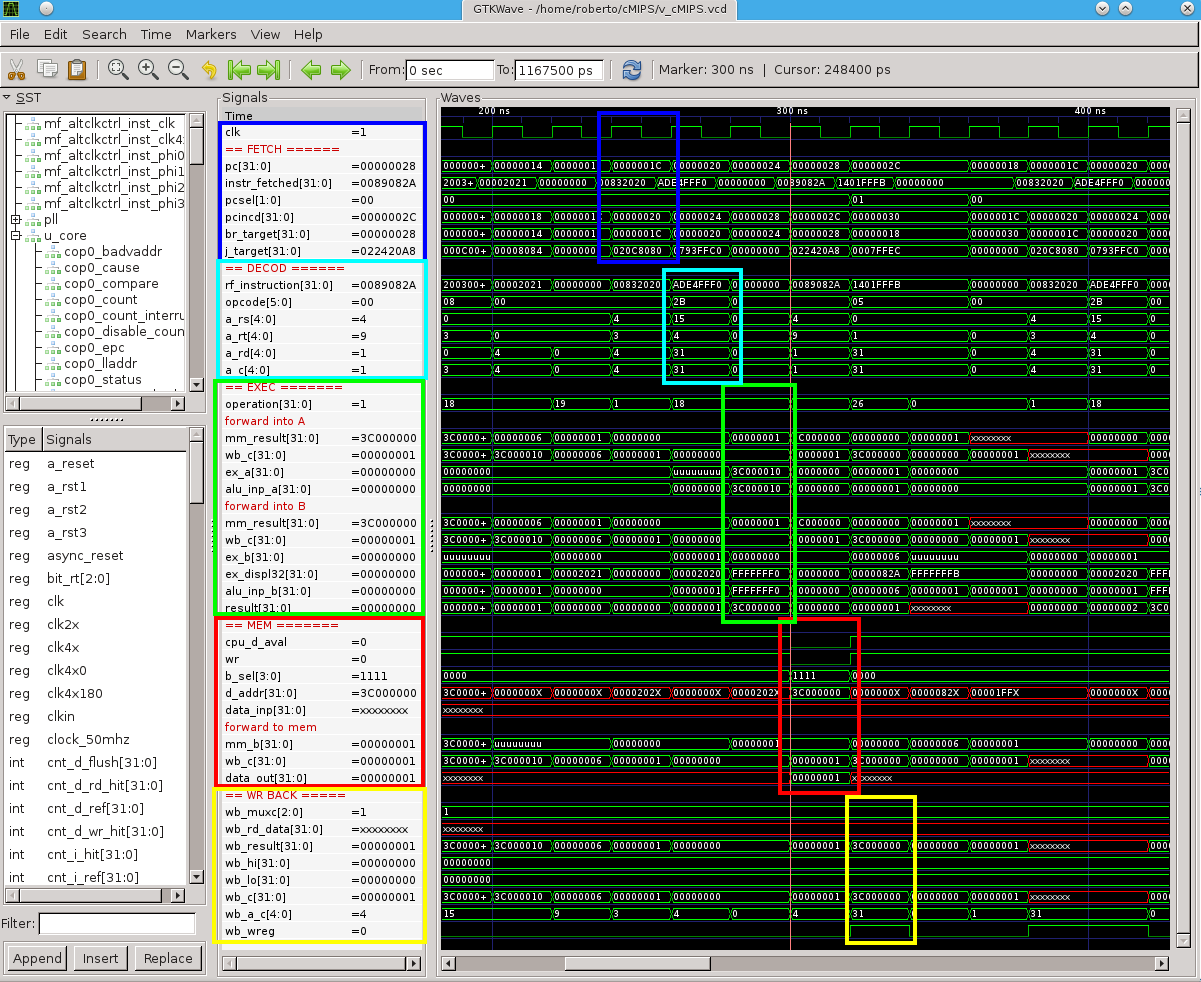 Usaremos o programa abaixo como base, e que executa corretamente num
processador sem adiantamento.
Copie o trecho de código para um arquivo chamado adianta.s, edite-o
se necessário e verifique a corretude dos resultados produzidos pelo
programa, que deve ser uma sequência de múltiplos de 16, representados em
hexadecimal.
Após editar, execute o comando abaixo para montar seu programa e executar a
simulação.
prompt: assemble.sh -v adianta.s && mv prog.bin data.bin .. && (cd .. ; run.sh -w -v pipe_Med.sav)&
Usaremos o programa abaixo como base, e que executa corretamente num
processador sem adiantamento.
Copie o trecho de código para um arquivo chamado adianta.s, edite-o
se necessário e verifique a corretude dos resultados produzidos pelo
programa, que deve ser uma sequência de múltiplos de 16, representados em
hexadecimal.
Após editar, execute o comando abaixo para montar seu programa e executar a
simulação.
prompt: assemble.sh -v adianta.s && mv prog.bin data.bin .. && (cd .. ; run.sh -w -v pipe_Med.sav)&
.include "cMIPS.s" .text .align 2 # alinhe em 2^2 .set noreorder # montador não deve reordenar as instruções .set noat # não use o registrador $1 como $at .globl _start # _start é um símbolo global (usado pelo ligador) .ent _start # ponto de entrada de _start _start: la $15,(x_IO_BASE_ADDR) addi $16,$0,6 addi $3,$0,1 add $4,$0,$0 nop nop nop lasso: add $4,$4,$3 # $4+1, $4 <- 1,2,3,4,5,6 nop nop nop add $5,$4,$4 # $5 <- $4*2 nop nop nop add $6,$5,$5 # $6 <- $5*2 nop nop nop add $7,$6,$6 # $7 <- $6*2 nop nop nop add $8,$7,$7 # $8 <- $7*2 nop nop nop sw $8,0($15) # "imprime" $8 na tela, em hexa slt $1,$4,$16 # terminou? nop nop nop bne $0,$1,lasso nop nop # drena segmentos nop nop nop wait # e termina a simulação .end _start # final de _start
Meça o número de ciclos necessários para executar a versão original de adianta.s (sem adiantamento), e compare-o com o número de ciclos depois que o código foi otimizado para tirar vantagem do adiantamento. O tempo simulado é mostrado na primeira linha da mensagem de fim de simulação. Transforme o tempo simulado em número de ciclos -- veja qual é a duração de cada ciclo na tela do GTKWAVE. Seus resultados (com e sem adiantamento) se alteram de forma significativa se considerarmos somente as instruções do laço? Quer dizer desde o ADD no endereço lasso: até o BNE.
6- Branch delay-slots
Altere novamente sua versão otimizada de adianta.s para preencher o delay-slot da instrução bne. Qual o ganho de desempenho com o preenchimento do delay-slot? O comportamento do processador é o esperado? Por que? Verifique se mais detalhes no diagrama de tempos o ajudam a diagnosticar a situação. Configure o gtkwave para mostrar os sinais de intertravamento que forçam os bloqueios (stalls) quando necessário. O diagrama de tempo mostra, no estágio de busca, os sinais XXX_stall, que indicam as condições XXX que provocam os bloqueios. Re-inicie o GTKWAVE para que ele mostre mais detalhes na tela: prompt: run.sh -w -v pipe_MAX.sav &7- Load delay-slots
O programa abaixo contém uma dependência de uso do load (load delay-slot) do lw para o addi. Este programa imprime a sequência de -9 até +10. Meça o tempo necessário para a execução deste programa e transforme o tempo simulado em número de ciclos. Otimize o código considerando que o circuito de adiantamento, verificado nos itens anteriores, está correto e compare o tempo de execução da versão otimizada com a versão original. Transforme o tempo simulado em número de ciclos e compare os números de ciclos das duas execuções. Salve o programa em ldslot.s, monte-o e execute a simulação. Configure o gtkwave para mostrar os sinais de intertravamento que forçam os bloqueios (stalls) quando necessário. O diagrama de tempo mostra, no estágio de busca, os sinais XXX_stall, que indicam as condições XXX que provocam os bloqueios. prompt: assemble.sh -v ldslot.s && mv prog.bin data.bin .. && (cd .. ; run.sh -w -v pipe_MAX.sav)&.include "cMIPS.s" .text .align 2 .set noreorder # montador não deve reordenar as instruções .globl _start .ent _start _start: la $15, x_DATA_BASE_ADDR la $16, x_IO_BASE_ADDR addi $3,$0,-10 # saída de -9 a +10 nop lasso: sw $3, 0($15) # armazena $3 em M[$15] lw $4, 0($15) # lê $4 de M[$15] nop nop nop addi $4,$4,1 # incrementa saída nop nop nop sw $4, 0($16) # escreve valor lido na saída do simulador move $3,$4 nop nop nop slti $8,$3,10 # já terminou? $3 < 10? nop nop nop bne $8,$0,lasso nop nop # drena segmentos nop nop nop wait # e termina a simulação .end _start
8- Adiantamento de Load para Store
O programa abaixo contém um laço que imprime de -10 a +9. O valor "da vez" é armazenado em memória e em seguida lido da memória e então enviado para a saída do simulador. O primeiro sw armazena o valor "da vez", que é lido pelo lw e em seguida "armazenado" no periférico pelo segundo sw. O que você deve verificar é se o adiantamento do lw para o segundo sw está implementado corretamente. Salve o programa abaixo em adiantalwsw.s, edite-o para verificar o adiantamento e então verifique a corretude da implementação. prompt: assemble.sh -v adiantalwsw.s && mv prog.bin data.bin .. && (cd .. ; run.sh -w -v pipe_Med.sav)&.include "cMIPS.s" .text .align 2 .set noreorder # montador não deve reordenar as instruções .globl _start .ent _start _start: la $15, x_DATA_BASE_ADDR la $16, x_IO_BASE_ADDR addi $3,$0,-10 # saída de -10 a +9 nop lasso: sw $3, 4($15) # armazena em M[$15 + 4] addi $3,$3,1 # incrementa saída lw $4, 4($15) # lê de M[$15 + 4] nop nop sw $4, 0($16) # escreve valor lido na saída do simulador addi $15,$15,4 # incrementa endereço/índice slti $8,$3,10 # já terminou? $3 < 10? nop nop nop bne $8,$0,lasso nop nop # drena segmentos nop nop nop wait # e termina a simulação .end _start