Documentos do Programa
Decidimos modularizar as funções do programa principal, para facilitar a compreensão do algoritmo, ficando com esses arquivos:
- lista.h.txt: O header das funções usadas no lista.c, com uma breve explicação de suas funcionalidades e parâmetros: [Ver Arquivo] [Baixar Arquivo]
- lista.c.txt: Onde estão implementada todas as funções do TAD Heap usado no programa principal: [Ver Arquivo] [Baixar Arquivo]
- Sort.h.txt: O header das funções utilizadas em Sort.c, com uma breve explicação de suas funções: [Ver Arquivo] [Baixar Arquivo]
- Sort.c.txt: Onde estão as funções responsáveis pelos algoritmos de ordenação que foram solicitadas no programa principal: [Ver Arquivo] [Baixar Arquivo]
- main.c.txt: O programa principal: [Ver Arquivo] [Baixar Arquivo]
Log dos testes
Nesse arquivo .txt está o log do nosso programa:
- Log.txt: O log gerado durante a execução dos testes selecionados: [Ver Arquivo] [Baixar Arquivo]
-
Acabamos nao imprimindo o vetor inteiro de 1024 elementos pois ficaria muito grande e
achamos que contaminaria o log, por isso, fizemos o sorteio dos 1024 elementos, usando
o
srand(time(NULL))para garantir a aleatoriedade dos numeros, e imprimimos as comparacoes e trocas que foram realizadas nos 3 algoritmos. E em seguida, para deixar visual fizemos o mesmo processo, com os mesmos algoritmos, mudando apenas o numero de elementos de 1024 para 32, só que dessa vez imprimindo o vetor original e os vetores ordenados, acompanhados de suas trocas e comparacoes.
Relatório
Relatório do trabalho prático da matéria Algoritmos e Estruturas de Dados II redigida pelo professor Elias P. Duarte Jr.
O relatório segue o modelo “diário” como indicado pelo professor.
-
Dia 01(23/10)
No primeiro dia, através de uma chamada de áudio via discord, apenas lemos o trabalho juntos e estruturamos a ideia e os arquivos necessários para a realização do trabalho, quase nada de código por enquanto. Criamos um repositório em grupo no Github, fizemos a README file. Além disso, anotamos dúvidas para tirar com o professor na aula do dia seguinte
-
Dia 02 (28/10)
- Agora, estávamos nos laboratórios do DINF. Após o esclarecimento de dúvidas com o professor, tínhamos uma ideia mais concreta do plano de ação. Criamos arquivos lista.h e lista.c onde estruturamos a struct paciente que seria usada (pela enfermeira chefe). Nesses arquivos também colocamos as funções do Heap que aprendemos em sala adaptadas para um vetor de structs. Decidimos criar funções para a manipulação de um vetor estático, onde o Heap era aplicado nesse vetor, como especificado pelo professor. Também fizemos o arquivo main.c, o arquivo que teria a interface interativa - um menu de opções - que permite que o usuário faça operações com os pacientes (inserir, remover, imprimir etc).
- (+- 2h40 de permanência no lab)
-
Dia 03(29/10)
- Através de uma chamada de áudio discord, nos prontificamos a finalizar a parte de comparações entre algoritmos de ordenação. Criamos arquivos Sort.h e Sort.c, onde colocamos as funções de ordenação do QuickSort e do SelectSort que aprendemos em sala. Nesses arquivos, também tivemos que colocar novamente as funções de manipulação de Heap, só que agora adaptada para manipular valores inteiros e não structs. Também resolvemos alguns erros do menu de operações do main. Além disso, enviamos um email ao professor para tirar dúvidas sobre os demais processos de trabalho (relatório, log e site).
- (+- 1h30 de chamada)
-
Dia 04(30/10)
- Aqui o programa já estava rodando e funcionando. Entretanto, percebemos que esquecemos de colocar a funcionalidade de alterar a prioridade do paciente. Então, nos juntamos em frente à Biblioteca de Ciência e Tecnologia com nossas máquinas pessoais (o dinf estava fechado) para consertar esse erro. Agora, ainda faltava produzir o log, relatório e a página web. Aproveitamos para estruturar o relatório
-
Dia 05(31/10)
- Aqui, finalizamos todos os demais processos necessários para entregar o projeto através de uma chamada de áudio Discord. Fizemos o Log, relatório e página Web.
Metodologia
O nosso vetor estático inicial era dessa forma:
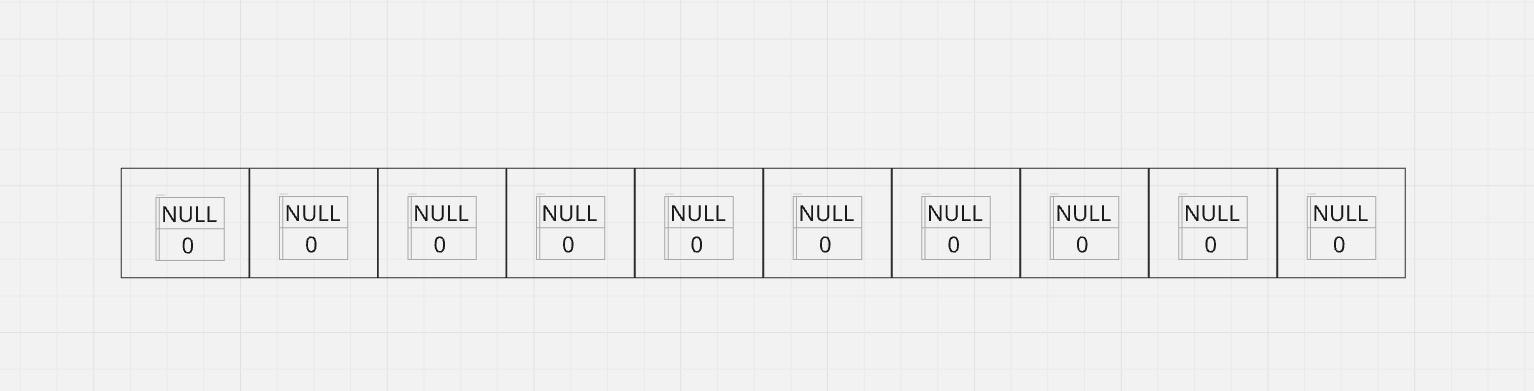
À medida que o usuário ia adicionando pacientes, a estrutura do vetor ficava dessa forma:
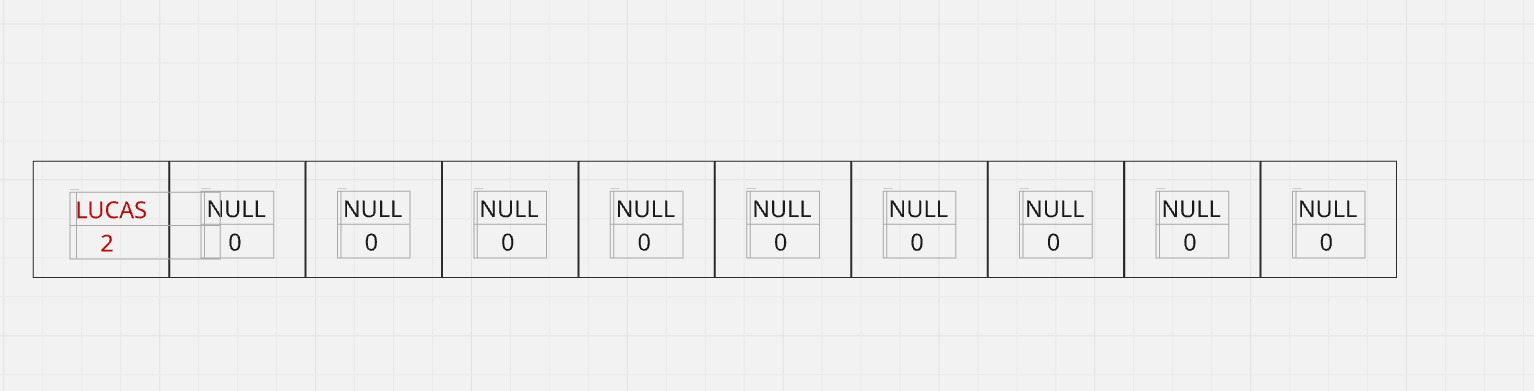
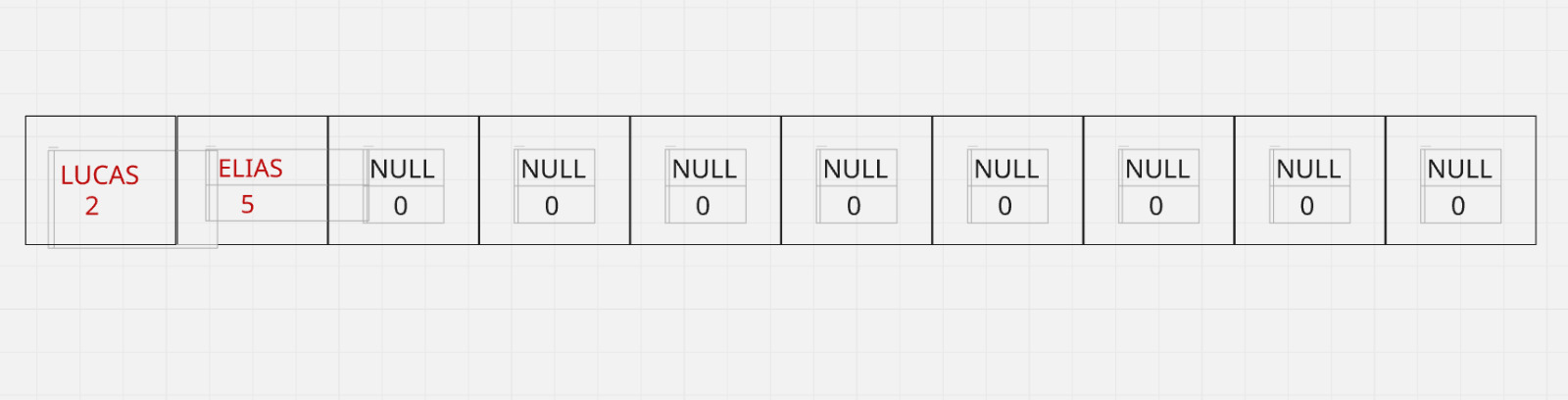
A função para imprimir o vetor, imprime apenas as structs que estavam em estado inicial (com nome NULL e prioridade zerada). Caso, o usuário insira algum paciente no vetor, ele é inserido seguindo a ordem do que seria um Min Heap, pois no nosso caso quanto menor o valor absoluto, maior a prioridade. Por exemplo: Se eu quiser adicionar um paciente com prioridade 5 (menor prioridade que 2) o paciente é inserido após o de prioridade maior.
Implementação das Funções
-
Função AlteraHeap
A lógica por trás de AlteraHeap: a função recebe como parâmetro a lista de pacientes (vetor), o número de pacientes, o índice do paciente - que corresponde à sua posição na lista - que vai ter sua prioridade alterada e o índice da nova prioridade. Quando o usuário clica na opção 5, tal opção que possibilita a troca de prioridades, é enviado 1 printf pedindo o índice do paciente que vai ser alterado, um scanf respectivo, outro printf pedido a nova prioridade. A nossa função AlteraHeap não ordena o Heap de uma vez, optamos por deixar desordenado para que o usuário que está interagindo com o programa possa usar a opção 4 -> que ordena o vetor decrescentemente. No início, até elaboramos uma lógica para ordenar o Heap nessa função, porém trocamos posteriormente. A lógica era a seguinte: suponhamos que temos um vetor de 10 posições; se o elemento do índice 5 do vetor tem sua prioridade trocada, podemos dizer que do índice 0 ao 4 o vetor é um organizado corretamente como um Heap, aí basta inserir os elementos dos índices 5 - 9 no Heap usando InsereHeap.
-
Função RemoveHeap
A lógica por trás de RemoveHeap: Ela remove sempre o elemento com menor prioridade do Heap de um vetor que já está ordenado, então, ela remove sempre o primeiro paciente da lista (o índice 1 do vetor). Como o primeiro elemento é eliminado, os outros são apenas “arrastados” para o lado. Para cobrir o buraco da posição 1 e realizar esse “arrastamento”, a função copia o nome e a prioridade de cada struct, a partir do índice 2, e cola na posição da esquerda. Por fim, a função troca o nome e a prioridade da última posição para “NULL” e 0 e decrementa o número de elementos (tamanho) do vetor. A função faz essa troca de nome e prioridade apenas como uma segunda camada de proteção, pois caso o decremento de espaços do vetor dê erro, a função não imprime o último paciente de qualquer maneira Essa função é usada unicamente quando a Enfermeira chefe deseja chamar o próximo paciente.
-
Função InicHeap
Como o Heap é implementado em um vetor estático, a função InicHeap simplesmente cria um vetor de 10 posições e adiciona neles structs com o nome “NULL” e prioridade 0. Para facilitar, colocamos que a função ImprimeHeap imprime apenas structs com prioridade diferente de 0 e nome diferente de NULL.
-
Função ImprimeHeap
A função ImprimeHeap imprime apenas structs do vetor que tem nome diferente de “NULL” e prioridade diferente de 0.
Contagem de Trocas e Comparações
Essa foi, sem dúvida, uma das partes mais trabalhosas do projeto. Não porque fosse difícil encontrar onde as trocas e comparações aconteciam, mas sim por entender o que realmente deveria ser contado. As trocas foram a parte mais simples, já que o padrão delas é bem característico: sempre envolvem o uso de uma variável auxiliar para armazenar temporariamente um valor antes da substituição. Isso deixou fácil identificar todos os pontos do código onde uma troca acontecia.
As comparações, por outro lado, geraram mais dúvida. No começo, parecia que bastava contar todos os
if e as condições dentro dos while. Mas, quando olhamos mais de perto,
percebemos que nem todas as comparações realmente dizem respeito à ordenação em si. Por exemplo,
condições como while (i > 1) ou if (esq < dir) apenas controlam o
fluxo do programa, sem comparar elementos do vetor.
Depois de pesquisar e discutir bastante, chegamos à conclusão de que existe uma diferença entre a parte teórica e a prática da análise de algoritmos. Na prática, toda comparação é de fato executada e consome tempo, mas, teoricamente, o foco da análise está nas comparações que influenciam o resultado da ordenação — ou seja, aquelas que envolvem diretamente os valores do vetor.
Por isso, optamos por seguir o ponto de vista teórico e contar apenas as comparações que realmente participam do processo de ordenação. As condições de controle, como as de parada ou de limite de laço, não foram incluídas. Assim, nossa contagem reflete melhor a lógica do algoritmo e permite comparar de forma mais justa o comportamento entre diferentes métodos de ordenação.
Com esse critério definido, padronizamos a forma de medir as comparações e trocas em todos os algoritmos, garantindo que os resultados fossem consistentes e focados no que realmente importa: o custo lógico da ordenação.