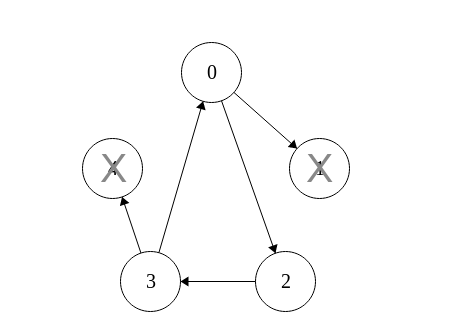
Neste algoritmo, um nodo sem-falha executa testes em sequência, até que encontre um outro nodo sem-falha, para então obter as informações de diagnóstico sobre os outros nodos presentes no sistema (exceto os nodos que já testou anteriormente).
Os nodos presentes no sistema podem ser representados por um grafo completo e os nodos sem-falhas foram um anel no grafo, conforme exibido na figura 1.
O trabalho foi dividido em 4 pequenas tarefas, implementadas a partir do código base passado pelo professor em sala de aula.
A tarefa 1 consistia em fazer com que cada nodo testasse o próximo no anel. Esta etapa foi feita em laboratório com o professor, e foi facilmente implementada com o acréscimo de uma estrutura condicional (IF/ELSE) quando a simulação faz um teste em um nodo. O próximo nodo é definido como:
(token+1)%N
Onde token indica qual nodo está sendo executado pelo sistema no momento, e N representa o número de nodos do sistema.
O teste é feito através da função do smpl status.
A tarefa 2 consistia em fazer com que cada nodo sem-falha executasse testes sequencialmente, até que fosse encontrado um outro nodo sem-falha. Isto foi implementado com a ajuda de uma estrutura de repetição (FOR), sendo que toda vez que o nodo atual (token) encontrar um outro nodo falho, então continua a andar no grafo procurando um nodo sem-falha. Quando este é encontrado, o FOR é quebrado.
Na tarefa 3 foi criado um vetor chamado STATE dentro da estrutura do nodo, de forma que cada nodo tenha um vetor STATE para armazenar a informação do nodo testado (0 - fault-free e 1 - faulty).
Estas informações são salvas dentro do IF já existente no código, onde é feito o teste através da função status e então o retorno é utilizado como informação para atualizar o vetor STATE do nodo.
A tarefa 4 permite que um nodo sem-falha, ao encontrar outro nodo sem-falha, obtenha as informações de diagnóstico daquele nodo, sabendo assim os estados de nodos que não foram testados por ele. Para cumprir esta tarefa foi apenas criado um FOR para efetuar a cópia do vetor STATE, dentro da condição do IF de quando o nodo encontra um outro nodo sem-falha.
Com isso, o algoritmo Adaptive DSD está implementado.
De acordo com a teoria vista em sala de aula do Adaptive DSD, a latência é definida como o número de rodadas de testes necessárias para completas o diagnóstico de um evento no pior caso.
Uma rodada de testes, por sua vez, é definida como o intervalo no qual todos os nodos sem-falhas do sistema completaram seus testes, ou seja, quando o anel completa uma volta. A latência do Adaptive DSD é N. Por exemplo, em um sistema com 5 nodos, onde 4 estão falhos, são necessárias 5 rodadas de teste para completar o diagnóstico. No melhor caso, sem nenhum nodo falho, é necessária apenas 1 rodada de testes para completar o diagnóstico.
Para a elaboração deste trabalho, NÃO foi criada uma condição que identifica o fim de um diagnóstico e interrompe a simulação. A condição em questão fica de certa forma até fora de questão, se considerarmos sistemas de grande escala, onde são possíveis milhares de nodos, pois a execução do diagnóstico demoraria muito para ser encerrada. Além disto, não há como garantir, em um sisema real, que um nodo nunca mais irá falhar, ou recuperar. Durante a elaboração deste trabalho, a simulação tem um tempo pré-determinado para executar e este tempo nunca é interrompido, a não ser por algum erro. Esta situação traz a tona duas características a serem observadas durante a análise dos resultados deste trabalho: