Next: Bibliografia Up: Linguagem C++ - Notas Previous: 1 Programação Básica em
As seções seguintes apresentam temas mais avançados da linguagem C++ , não abordadas em sala de aula. Elas podem ser estudadas pelo aluno como atividade complementar, pois apresentam mecanismos bastantes úteis em programas mais complexos (tratamento de arquivos e textos, manipulação dinâmica de memória, etc.).
Há alguns operadores em C++ que são equivalentes as seguintes expressões (que são bastante comuns em programas):
k = k + 1; j = j - 1;
Estes operadores adicionais, que são ++ e - -, podem ser usados para encurtar as operações acima:
k++; j--;
Estes operadores também podem ser colocados depois do nome da variável:
++k; --j;
O fato do operador de incremento ser colocado antes ou depois da variável não altera o efeito da operação - o valor da variável é incrementada ou decrementada de um. A diferença entre os dois casos é QUANDO a variável é incrementada. Na expressão k++, o valor de k é primeiro usado e então é incrementada - isto é chamado pós-incremento. Na expressão ++k, k é incrementado primeiro, e então o valor (o novo valor) de k é usado - isso é chamado pré-incremento.
A diferença é ilustrada nos seguintes exemplos:
int main()
{
int k = 5;
cout << "k1 = " << k << endl;
cout << "k2 = " << k++ << endl;
cout << "k3 = " << k << endl;
}
O programa acima (que usa pós-incremento) imprimirá o seguinte:
k1 = 5
k2 = 5
k3 = 6
A segunda linha impressa com o valor de k é 5 porque o valor de k++ era 5, e k é 6 depois da impressão.
Para o programa:
int main()
{
int k = 5;
cout << "k1 = " << k << endl;
cout << "k2 = " << ++k << endl;
cout << "k3 = " << k << endl;
}
O programa, que usa pré-incremento, terá a seguinte saída:
k1 = 5
k2 = 6
k3 = 6
A segunda linha impressa é 6 porque o valor de ++k é 6.
Os operadores de atribuição não podem ser usados com expressões aritméticas. Por exemplo, as expressões
(ack + 2)++;
(nope + 3) += 5;
resultarão em erros de compilação.
Finalmente, quando usar o operador de incremento em um cout, tome cuidado para não fazer o seguinte:
cout << ++uhoh << uhoh * 2 << endl;
Embora isso seja perfeitamente legal em C++ , os resultados não são garantidados que sejam consistentes. A razão para isso é que não há garantia que os argumentos do cout sejam avaliados em uma determinada ordem. O resultado do cout será diferente dependendo se ++uhoh é avaliado primeiro ou depois de uhoh * 2.
A solução para este problema é escrever o seguinte:
++uhoh;
cout << uhoh << uhoh * 2 << endl;
Já que incremento e decremento são formas de atribuição, o operando deve ser um lvalue. O valor de uma expressão de incremento ou decremento depende se o operador é usado na notação PRé ou PóS fixada (x++, ++x, x--, --x). Se for pré-fixada, o valor da expressão é o novo valor após o incremento ou decremento. Se for pós-fixada, o valor da expressão é o valor antigo (antes do incremento ou decremento). Por exemplo no caso de incremento, a expressão:
x++ tem o valor de x
++x tem o valor de x + 1
Note que não importando a notação usada, o valor de x (o conteúdo do endereço de memória associada a x) será x + 1. A diferença está no valor das expressões x++ e ++x, não no valor de x (em ambos os casos o valor de x será incrementada de um).
Às vezes, problemas podem acontecer devido o fato que C++ não especifica a ordem de avaliação dos operadores em uma operação binária. Em outras palavras, em expressões como a + b ou a < b, não há maneira de saber se o valor de a será avaliado antes ou depois de b (pense em a e b como sendo qualquer expressão, não somente variáveis.) Qual deles será avaliado primeiro é particular de cada compilador, e diferentes compiladores em máquinas diferentes podem ter resultados diferentes. Portanto, se a avaliação de um dos operadores pode alterar o valor do outro, o resultado pode ser diferente dependendo da ordem de avaliação. Portanto, em expressões do tipo x + x++, o valor pode diferir dependendo do compilador utilizado. Isto porque não sabemos quando exatamente o incremento de x ocorre. Outros maus exemplos: y = x + x-- e x = x++. De forma geral, para evitar este problema, não utilize senteças como estas.
Como podemos ver, os operadores de incremento/decremento, e os operadores de atribuição aritmética vistos até aqui funcionam de forma similar ao comando de atribuição. O lado esquerdo da expressão de atribuição aritmética e o operando de incremento/decremento devem ser um lvalue. O valor da expressão da é igual ao valor da sentença de atribuição correspondente. Por exemplo:
x += 3 é igual a x = x + 3 e tem valor x + 3
x *= y + 1 é igual a x = x * (y + 1) e tem valor x * (y + 1)
y = i++ é igual a y = i, i = i + 1; e tem valor i
y = ++i é igual a i = i + 1, y = i; e tem valor i + 1
O que é impresso pelos dois programas abaixo?
#include <iostream>
using namespace std;
int main() {
int n1, n2, n3;
cout << "Entre com um numero inteiro: ";
cin >> n1;
n1 += n1 * 10;
n2 = n1 / 5;
n3 = n2 % 5 * 7;
n2 *= n3-- % 4;
cout << n2 << " " << n3 << " " << (n2 != n3 + 21) << endl;
}
A tabela de precedência abaixo mostra a posição dos operadores vistos aqui, incluindo a atribuição aritmética e decremento/incremento.
| Operador | Associatividade |
() [] -> . |
esquerda para direita |
! - ++ -- * \& |
direita para esquerda |
* / % |
esquerda para direita |
+ - |
esquerda para direita |
< <= > >= |
esquerda para direita |
== != |
esquerda para direita |
&& |
esquerda para direita |
|| |
esquerda para direita |
= += -= *= /= %= |
direita para esquerda |
, |
esquerda para direita |
Expressões não tem somente um valor, mas também tem um tipo associado.
Se ambos os operandos de uma operação aritmética binária são do mesmo tipo, o resultado terá o mesmo tipo. Por exemplo:
3 + 5 é 8, e o tipo é int
3.5 + 2.25 é 5.75, e o tipo é double
O único comportamento não óbvio é a da divisão de inteiros:
30 / 5 é 6
31 / 5 é 6
29 / 5 é 5
3 / 5 é 0
Lembre-se de evitar escrever algo como 1 / 2 * x significando
![]() . Você sempre obterá o valor 0 porque 1 / 2 * x é (1 / 2) * x que é 0 * x que é 0. Para
obter o resultado desejado, você poderia escrever 1.0 / 2.0 * x.
. Você sempre obterá o valor 0 porque 1 / 2 * x é (1 / 2) * x que é 0 * x que é 0. Para
obter o resultado desejado, você poderia escrever 1.0 / 2.0 * x.
Valores podem ser convertidos de um tipo para outro implicitamente, da forma já comentada anteriormente.
Em expressões envolvendo operadores binários com operandos de tipos diferentes, os valores dos operandos são convertidos para o mesmo tipo antes da operação ser executada: tipos mais simples são ``promovidos'' para tipos mais complexos. Portanto, o resultado da avaliação de uma expressão com operandos de tipos diferentes será o tipo do operando mais complexo. Os tipos em C++ são (do mais simples para o mais complexo):
char < int < long < float < double
O sinal de < significa que o tipo da esquerda é promovido para o tipo da direita, e o resultado será do tipo mais a direita. Por exemplo:
3.5 + 1 é 4.5
4 * 2.5 é 10.0
Esta regra estende-se para expressões envolvendo múltiplos operadores, mas você deve se lembrar que a precedência e associatividade dos operadores pode influenciar no resultado. Vejamos o exemplo abaixo:
int main()
{
int a, b;
cout << "Entre uma fracao (numerador e denominador): ";
cin >> a >> b;
cout << "A fracao em decimal e " << 1.0 * a / b << endl;
}
Multiplicando por 1.0 assegura que o resultado da multiplicação de 1.0 por a será do tipo real, e portanto, a regra de conversão automática evitará que o resultado da divisão seja truncado. Note que se tivéssemos primeiro feito a divisão a/b e depois multiplicado por 1.0, embora o tipo da expressão a/b*1.0 seja do tipo double, o valor da expressão seria diferente do valor de 1.0 * a/b. Por que ?
Em atribuições, o valor da expressão do lado direito é convertido para o tipo da variável do lado esquerdo da atribuição. Isto pode causar promoção ou ``rebaixamento'' de tipo. O ``rebaixamento'' pode causar perda de precisão ou mesmo resultar em valores errados.
Em operações de atribuição, atribuir um int em um float causará a conversão apropriada, e atribuir um float em um int causará truncamento. Por exemplo:
float a = 3; é equivalente a a = 3.0
int a = 3.1415; é equivalente a a = 3 (truncado)
Basicamente, se o valor da expressão do lado direito da atribuição é de um tipo que não cabe no tamanho do tipo da variável do lado esquerdo, resultados errados e não esperados podem ocorrer.
Os tipos de dados básicos em C++ podem estar acompanhados por modificadores na declaração de variáveis. Tais modificadores são: long, short, signed e unsigned. Os dois primeiros têm impacto no tamanho (número de bits) usados para representar um valor e os dois últimos indicam se o tipo será usado para representar valores negativos e positivos (signed) ou sem este modificador) ou apenas positivos (unsigned).
A Tabela 4 mostra uma lista completa de todos os tipos
de dados em C++ , com e sem modificadores:
C++ tem um operador para alterar o tipo de um valor explicitamente. Este operador é chamado de cast. Executando um cast de tipos, o valor da expressão é forçado a ser de um tipo particular, não importando a regra de conversão de tipos.
O formato do cast de tipos é:
(![]() -
-![]() -
-![]() )
)![]()
O parênteses NÃO é opcional na expressão acima.
Podemos usar o cast de tipos da seguinte forma:
int fahr = 5; float cels; cout << "Valor = " << (float) fahr << endl; cels = (float)5 / 9 * (fahr - 32); cout << "celsius = " << (int) cels << endl;
Agora que conhecemos o operador de cast de tipo podemos reescrever o programa que faz a conversão de fração para decimal.
int main()
{
int a, b;
cout << "Entre com uma fracao (numerador e denominador): ";
cin >> a >> b;
cout << "A fracao em decimal e " << (float) a / b << endl;
}
O cast de tipo tem a maior precedência possível, portanto podemos fazer o cast de a ou de b para ser do tipo float, e não há necessidade de parênteses extra. No exemplo acima, o cast causa o valor da variável a ser convertido para float, mas não causa mudança no tipo da variável a. O tipo das variáveis é definido uma vez na declaração e não pode ser alterado.
A sentença switch é outra maneira de fazer decisões múltiplas. Ele pode ser usado para testar se uma dada expressão é igual a um valor constante e, dependendo do valor, tomar determinadas ações.
O formato da sentença switch é:
switch (expressao) {
case expressao-constante 1:
sentencas 1
case expressao-constante 2:
sentencas 2
![]()
default:
sentencas n
}
![\includegraphics[scale=0.85]{switch}](notas-img58.png)
A sentença switch primeiro avalia a expressão. Se o valor da expressão for igual a uma das expressões constantes, as sentenças que seguem o case são executados. Se o valor da expressão não for igual a nenhuma das constantes, as sentenças que seguem default são executadas.
As sentenças que seguem o case são simplesmente uma lista de sentenças. Esta lista pode conter mais de uma sentença e não é necessário colocá-las entre chaves ({ e }). A lista de sentenças também pode ser vazia, isto é, você pode não colocar nenhuma sentença seguindo o case.
Também não é obrigatório colocar o default. Só o use quando for necessário.
Note no diagrama acima que TODAS as sentenças que seguem a constante com o valor igual ao da expressão serão executados. Para que se execute APENAS as sentenças que seguem o case que seja igual ao valor da expressão precisamos usar a sentença break, que veremos em seguida.
O break faz com que todas as sentenças que o seguem dentro da mesma sentença switch sejam ignorados. Ou seja, colocando a sentença break no final de uma sentença case faz com que as sentenças que seguem os cases subsequentes não sejam executadas. Em geral, é este o comportamento desejado quando se usa o switch, e cases sem o break no final são de pouca utilidade. Portanto, o uso de sentenças case sem o break devem ser evitados e quando utilizados devem ser comentados ao lado com algo como /* continua proxima sentenca - sem break */.
Com a sentença break o diagrama de fluxo fica:
![\includegraphics[scale=0.85]{break}](notas-img59.png)
Note a similaridade com o diagrama da sentença else-if e a diferença com o diagrama da sentença switch acima.
O próximo programa tem a mesma função de calculadora do programa anterior, porém utilizando a sentença switch.
#include <iostream> using namespace std; int main( ){ float num1, num2; char op; // obtem uma expressao do usuario cout << "Entre com numero operador numero\n"; cin >> num1 >> op >> num2; switch (op) { case '+': cout << " = " << setprecision(2) << num1 + num2; break; case '-': cout << " = " << setprecision(2) << num1 - num2; break; case '*': cout << " = " << setprecision(2) << num1 * num2; break; case '/': cout << " = " << setprecision(2) << num1 / num2; break; default: cout << " Operador invalido."; break; } cout << endl; }
Como mencionado anteriormente, é possível não colocar nenhuma sentença seguindo um case. Isso é útil quando diversas sentenças case (diversas constantes) têm a mesma ação.
Por exemplo, podemos modificar o programa acima para aceitar x e
X para multiplicação e \ para divisão. O programa fica
então:
#include <iostream> using namespace std; int main( ){ float num1, num2; char op; // obtem uma expressao do usuario cout << "Entre com numero operador numero\n"; cin >> num1 >> op >> num2; switch (op) { case '+': cout << " = " << setprecision(2) << num1 + num2; break; case '-': cout << " = " << setprecision(2) << num1 - num2; break; case '*': case 'x': case 'X': cout << " = " << setprecision(2) << num1 * num2; break; case '/': case '\\': cout << " = " << setprecision(2) << num1 / num2; break; default: cout << " Operador invalido."; break; } cout << endl; }
Há outro comando de repetição em linguagem C++ . O do...while é bastante parecido com while, com a diferença que a expressão de teste é avaliada DEPOIS que o corpo da repetição é executado.
O formato do do...while é:
do
corpo da repetição
while (expressão teste )
![\includegraphics[scale=1.0]{do-while}](notas-img60.png)
O exemplo abaixo usa o do...while:
int contador = 0;
do {
cout << "contador = " << contador << endl;
contador += 1;
} while( contador < 5 );
cout << "ACABOU !!!!\n";
A execução deste programa é idêntico ao primeiro exemplo mostrado para o comando while, com a expressão de teste mudada para o final.
Saída:
contador = 0
contador = 1
contador = 2
contador = 3
contador = 4
ACABOU !!!!
O do...while é usado quando o corpo da repetição deve ser executado pelo menos uma vez. Um exemplo comum disto é o processamento da entrada de um programa.
#include <iostream> using namespace std; int main( ){ int num; cout << "Entre com um numero par:\n"; do{ cin >> num; } while( num % 2 != 0 ); cout << "Obrigado.\n"; }
Exemplo de execução:
Entre com um numero par:
3
1
5
4
Obrigado.
Neste caso, o valor da variável num é digitado pelo
usuário. Depois disso, o teste é executado para verificar se o número é
par (o teste num % 2 != 0 é falso se num é par já que o
resto da divisão de qualquer número par por 2 é zero).
É possível escrever o programa acima usando while:
#include <iostream> using namespace std; int main( ){ int num; // Atribui um numero impar a num cout << "Entre com um numero par:\n"; num = 1; while( num % 2 != 0 ){ cin >> num; } cout << "Obrigado.\n"; }
O problema com este programa é que a variável num deve ser inicializada com um valor que torne o teste do laço verdadeiro. Neste exemplo, é simples encontrar tal valor. Para uma expressão teste mais complicada, isso pode não ser tão fácil.
Em uma estrutura de repetição, o break faz com que todas as sentenças que o seguem dentro sejam ignorados. Além disso, o break também TERMINA a repetição, fazendo com que o programa continue sua execução APÓS o bloco da repetição. A expressão da repetição e a reinicialização (no caso do for) não são avaliadas após a execução de um break.
Em uma estrutura de repetição, o continue faz com que todas as sentenças que o seguem sejam ignorados. Além disso, esta sentença faz com que a reinicialização e a expressão da repetição sejam avaliadas e a execução do bloco de repetição é iniciado novamente.
Essencialmente, o continue significa ``ignore o restante do bloco de repetição e parta para a próxima interação''.
Em muitos programas, variáveis do tipo int são utilizadas não por suas propriedades numéricas, mas para representar uma escolha dentre um pequeno número de alternativas. Por exemplo:
int sexo; // masculino = 1 , feminino = 2 int cor; // vermelho = 1 , amarelo = 2 , verde = 3
A utilização de códigos para representar os valores que uma variável poderá assumir, certamente compromete a clareza da estrutura de dados do programa, tornando sua lógica obscura e inconsistente. Por exemplo:
cor = 3; if( sexo == 2 ) ... cor = cor + sexo; for( cor = 1; cor < 10; cor ++ )...
Um tipo enumerado permite definir uma lista de valores que uma variável deste tipo poderá assumir. A definição de um tipo enumerado é feita da seguinte forma:
Exemplos de definição de tipos enumerados:
enum TpCores {VERMELHO, AMARELO, VERDE};
enum TpDias {SEG, TER, QUA, QUI, SEX, SAB, DOM};
enum TpSexos {MASCULINO, FEMININO};
Variáveis destes tipos são definidas da seguinte forma:
enum TpCores var1, var2; enum TpDias var3;
Agora, é possível dar valores a estas variáveis, por exemplo:
var1 = AMARELO; var3 = QUI;
é um erro usar valores não definidos na declaração do tipo. A expressão var2 = AZUL; causa erro de compilação.
Internamente, o compilador trata variáveis enumeradas como inteiros. Cada valor na lista de valores possíveis corresponde a um inteiro, começando com 0 (zero). Portanto, no exemplo enum TpCores, VERMELHO é armazenado como 0, AMARELO é armazenado como 1, e VERDE é armazenado como 2.
Utilização de tipos enumerados
Variáveis de tipos enumerados são geralmente usados para clarificar a operação do programa. Considere o seguinte trecho de programa que codifica dias da semana como inteiros (sendo sabado = 5 e domingo = 6) para verificar se o dia do pagamento cai no final de semana e altera a dia para a segunda-feira seguinte.
#include <iostream>
using namespace std;
// prototipo da funcao que dada a data, retorna o dia da semana.
// seg=0, ter=1, qua=2, qui=3, sex=4, sab=5, dom=6
int diaDaSemana( int dia, int mes, int ano );
int main(){
int diaPgto, mesPgto, anoPgto;
int diaSem;
cout << "Entre com a data de pagamento (dd mm aa): ";
cin >> diaPgto >> mesPgto >> anoPgto;
diaSem = diaDaSemana( diaPgto, mesPgto, anoPgto );
if( diaSem == 5 )
diaPgto = diaPgto + 2;
else if( diaSem == 6 )
diaPgto++;
cout << "Data do pagamento: " << diaPgto << "/" << mesPgto << "/"
<< anoPgto << endl;
}
Este programa ficaria mais legível se ao invés de codificar os dias da semana como inteiros e colocar a codificação como comentário, utilizar tipos enumerados. O programa ficaria então
#include <iostream>
using namespace std;
enum TpSemana {SEG, TER, QUA, QUI, SEX, SAB, DOM};
// prototipo da funcao que dada a data, retorna o dia da semana
enum TpSemana diaDaSemana( int dia, int mes, int ano );
int main(){
int diaPgto, mesPgto, anoPgto;
int diaSem;
cout << "Entre com a data de pagamento (dd mm aa): ";
cin >> diaPgto >> mesPgto >> anoPgto;
diaSem = diaDaSemana( diaPgto, mesPgto, anoPgto );
if( diaSem == SAB )
diaPgto = diaPgto + 2;
else if( diaSem == DOM )
diaPgto++;
cout << "Data do pagamento: " << diaPgto << "/" << mesPgto << "/"
<< anoPgto << endl;
}
Note que a função diaDaSemana agora retorna apenas um dos valores da lista SEG, TER, QUA, QUI, SEX, SAB, DOM e portanto, no programa principal ao invés de testar se o diaSem == 5 podemos escrever diaSem == SAB, o que torna o programa muito mais legível.
A ênfase aqui será em como funções funcionam. O que acontece quando uma função é chamada ? A que variável um nome está se referenciando?
O tratamento em tempo de execução de um nome de variável em C++ é simples: um nome de variável é ou uma variável local (a função) ou uma variável global (definida fora de qualquer função).
Em C++ , todas as funções tem que ser definidas. Para cada função deve ser definido um protótipo. O protótipo é escrito fora de qualquer função. Desta forma, nomes de funções são visíveis para todas as outras funções que podem então invocá-las. A função main() é especial: é onde a execução do programa começa, e o protótipo de main() pode ser omitido.
Uma definição de função consiste de quatro partes:
{ }) contendo definição de variáveis e outras
sentenças. Em C++ , não se pode definir uma função dentro de outra.
Para funções com argumentos: uma função é chamada dando o seu nome e uma lista de argumentos (expressões que são avaliadas e cujos valores são atribuídos para os correspondentes parâmetros formais da função).
Por exemplo, suponha que triang![]() area() e circ
area() e circ![]() area() sejam funções que calculam a área de triângulos e
círculos, respectivamente. Seus protótipos são:
area() sejam funções que calculam a área de triângulos e
círculos, respectivamente. Seus protótipos são:
float triang_area(float , float); float circ_area(float);
Estas funções podem chamadas de dentro de outras funções. Os argumentos reais com os quais elas são chamadas podem ser expressões constantes, or variáveis locais, ou qualquer expressão cuja avaliação resulte em valores do tipo float (inteiros são convertidos para float da mesma forma que ocorre com atribuição de inteiros para variáveis do tipo float). Alguns exemplos de chamadas:
float area2, area3, area4, area5, base, altura, raio; cout << "area do triangulo = " << triang_area(0.03, 1.25); base = 0.03; altura = 1.25; area2 = triang_area(base, altura); area3 = triang_area(1.6, altura); area4 = triang_area( 0.03 + base, 2 * altura); raio = base + altura; area5 = triang_area(raio, circ_area(raio));
A última sentença do exemplo acima atribui a variável area5 a área de um triângulo cuja base é igual ao valor da variável raio e a altura é igual a area de um círculo de raio igual ao valor da variável raio.
Quando um programa é executado, somente uma única função tem o controle em determinado momento. Falaremos mais sobre o que acontece quando uma função é chamada mais tarde nestas notas de aula.
Variáveis locais que são definidas dentro da função devem ser inicializadas com algum valor antes de serem usadas. Caso contrário, o seu valor é indefinido.
Já que parâmetros formais (argumentos) são variáveis locais da função, eles podem ser usados no corpo da função. Eles não devem ser definidos dentro da função (sua definição já está no cabeçalho da função). Os parâmetros formais não precisam ser inicializados. Seus valores são fornecidos pelo chamador da função através dos argumentos reais.
Considere o seguinte exemplo:
/***************************************************************** * Um programa que calcula a area de triangulos e circulos. * A base, altura e raio sao fornecidos pelo usuario. * A saida do programa e a area do triangulo e circulo. *****************************************************************/ #include <iostream> using namespace std; #define PI 3.1415 /******************* prototipos *******************/ float triang_area(float, float); float circ_area(float); /******************* definicao de funcoes *******************/ main() { /* definicao das variaveis locais */ float base, altura, raio; /* dialogo de entrada */ cout << "\nEntre com a base e altura do triangulo: "; cin >> base >> altura; cout << "\nEntre com o raio do circulo: "; cin >> raio; /* chama as funcoes e imprime o resultado */ cout << "Area do triagulo com base e altura " << base << " e " << altura << " = " << triang_area(base, altura) << endl;; cout << "Area do circulo com raio " << raio << " = " << circ_area(raio) << endl; } /***************************************************************** * funcao: triang_area * calcula a area de um triangulo dada a base e altura * Entrada: base e altura do triangulo * Saida: area do triangulo *****************************************************************/ float triang_area(float base, float alt) { return 0.5*base*alt; } /***************************************************************** * funcao: circ_area * calcula a area de um circulo dado o raio * Entrada: raio do circulo * Saida: area do circulo *****************************************************************/ float circ_area(float r) { return PI*r*r; }
Este programa C++ consiste de três funções, main(), triang_area(), e circ_area(). main() tem variáveis locais chamadas base, altura e raio; triang_area() tem como variáveis locai seus parâmetros formais, base e alt; circ_area() tem como variável local seu parâmetro formal r.
Em geral, uma variável local só existe durante a execução da função na qual ela está definida. Portanto, variáveis locais existem desde o momento que a função é chamada até o momento em que a função é completada. Tais variáveis são chamadas de automatic. Em C++ , uma variável pode ser definida como sendo static. Neste caso, uma variável local não é visível de fora do corpo da função, mas ela não é destruída no final da função como variáveis automáticas são. Cada vez que a função é chamada, o valor das variáveis static é o valor final da variável da chamada anterior.
Até este momento, todas as variáveis que vimos são definidas dentro de funções (no corpo da função ou como parâmetros formais). é possível também definir variáveis fora das funções. Tais variáveis são chamadas de variáveis globais ou externas. O formato da definição de variáveis globais é o mesmo da definição de variáveis locais. A única diferença é onde a variável é definida: variáveis globais são definidas fora de qualquer função. Ao contrário das variáveis locais, variáveis globais podem ser vistas por todas as funções definidas após a definição das variáveis globais.
Nós temos usado declarações ``globais'' este tempo todo - por exemplo, as declarações de protótipos de funções. Elas são declaradas fora de qualquer função e podem ser vistas por qualquer função que estão após sua declaração.
No exemplo seguinte, uma variável saldo que é atualizada por três funções diferentes é definida como uma variável global. As três funções que a atualizam não chamam uma a outra.
/***************************************************************** * Caixa eletronico simples * o saldo e o valor a ser alterado e entrado pelo usuario * a saida do programa e' o saldo atualizado, incluindo juros *****************************************************************/ #include <iostream> using namespace std; #define JUROS 0.07 /******************* prototipos *******************/ void credito(float); void debito(float); void juros(void); /******************* globais *******************/ float saldo; /* saldo atual; * Alterada em: credito(), debito(), juros(), main() * Lida em: */ /*********************** definicao de funcoes ***********************/ main() { float valor; // valor a ser depositado/retirado cout << "Entre com o saldo atual: "; cin >> saldo; cout << "Deposito: "; cin >> valor; credito(valor); cout << "Retirada: "; cin >> valor; debito(valor); juros(); cout << "Juros " << JUROS * 100 << "%.\n"; cout << "Saldo = " << saldo << endl; } /***************************************************************** * Deposita um valor; atualiza a variavel global saldo * Entrada: valor a ser depositado * Saida: nenhum *****************************************************************/ void credito(float val) { saldo += val; } /***************************************************************** * Debita um valor; atualiza a variavel global saldo * Entrada: valor a ser debitado * Saida: nenhum *****************************************************************/ void debito(float val) { saldo -= val; } /***************************************************************** * Acumula juros; atualiza a variavel global saldo; juros: RATE * Entrada: nenhuma * Saida: nenhuma *****************************************************************/ void juros(void) { saldo += (saldo * JUROS); }
Um exemplo de execução do programa:
Entre com o saldo atual: 1000
Deposito: 200
Retirada: 80
Juros 7%.
Saldo = 1198.40
Variáveis globais devem ser usadas SOMENTE quando muitas funções usam muito as mesmas variáveis. No entanto, o uso de variáveis globais é perigoso (e não recomendado) porque a modularidade do programa pode ser afetada. Uma variável global pode ser alterada de dentro de uma função, e esta alteração pode influir no resultado de uma outra função, tornando-a incorreta (em um exemplo dado posteriormente nestas notas, duas chamadas a função soma_y() com o mesmo argumento (zero) produz resultados diferentes, 100 e 300).
Quando variáveis globais são utilizadas, deve ser dado a elas nomes descritivos e um breve comentário qual a finalidade da variável e quais funções a acessam.
Neste curso, você utilizará variáveis globais SOMENTE QUANDO FOR DADO PERMISSãO PARA FAZÊ-LO. Caso contrário, não é permitido utilizá-las (ou seja, serão descontados pontos).
Como já discutimos anteriormente, uma variável é uma abstração de dados que nós usamos em um programa. A variável representa um endereço de memória onde os valores são armazenados. Durante a execução do programa, valores diferentes poder ser armazenados neste endereço. Quando uma variável é definida, o nome da variável é ``atrelada'' a um endereço específico na memória. Até este momento, já discutimos o que é o nome de uma variável, seu endereço, tipo e valor. Outra característica que apresentaresmo agora é o escopo. O escopo de uma variável refere-se a parte do programa onde podemos utilizar a variável. Em outras, palavras, uma variável é ``visível'' dentro do seu escopo.
O escopo de uma variável local é a função na qual ela é definida. Os parâmetros formais de uma função também são tratados como variáveis locais.
O escopo de uma variável global é a porção do programa depois da definição da variável global (a partir do ponto onde ela é definida até o final do programa).
Se o nome de uma variável global é idêntico a uma variável local de uma função, então dentro desta função em particular, o nome refere-se a variável local. (Embora tais conflitos devem ser evitados para evitar confusão).
Por exemplo, considere o seguinte programa:
int valor = 3; /* definicao da variavel global */
int main()
{
/* definicao local de valor */
int valor = 4;
cout << valor << endl;
}
A saída do programa acima será 4 já que valor refere-se a definição local.
Considere outro exemplo:
#include <iostream> using namespace std; int soma_y(int); int soma_yy(int); int y = 100; // variavel global main() { int z = 0; // variavel local cout << soma_y(z) << endl; cout << soma_yy(z) << endl; cout << soma_y(z) << endl; } int soma_y(int x) { return x + y; // x e' variavel local, y e' global } int soma_yy(int x) { y = 300; // y e' variavel global return x + y; // x e' variavel local }
Vamos seguir a execução deste programa. Primeiro, a variável global y é criada e inicializada com 100. Então, a execução da função main() comeca: é alocado espaço na memória para a variável local z. Esta variável é inicializada com 0. Considere a primeira sentença cout :
cout << soma_y(z) << endl;
Esta é uma chamada para cout . Os parâmetros reais desta chamada
é a expressão soma_y(z). Ela consiste da chamada da função soma_y(). O valor desta expressão é o resultado retornado por soma_y(). Qual o resultado? A função soma_y é chamada com
o parâmetro real z. Como z = 0, este é o valor que será
passado para a função soma_y; o 0 é copiado para o
parâmetro formal x da função soma_y(). Portanto, durante
a excução da primeira chamada a função soma_y(), o valor da
expressão x + y será 0 + 100, que é 100. Portanto, o valor
da primeira chamada soma_ y(z) é 100, e este número será
impresso com o primeiro cout em main(). Agora considere a
segunda sentença:
cout << soma_yy(z) << endl;
Quando a função soma_yy(z) é chamada, o valor de z (a
variável local z) ainda é 0, portanto novamente 0 é
copiado para o parâmetro formal int x da função soma_yy.
Quando a execução de soma_yy() começa, ela primeiro troca o
valor da variável global y para 300 e então retorna o valor
de x + y, que neste caso é 0 + 300. Portanto, o valor
desta chamada a soma_yy(z) é 300, e este número será
impresso pelo segundo cout em main().
Por último,
considere a terceira sentença:
cout << soma_y(z) << endl;
Quando a função soma_y(z) é chamada, o valor de z ainda é
0, portanto, 0 é copiada para o parâmetro formal int
x da função soma_y(). Quando soma_ y() é executada pela
segunda vez, a variável global y foi modificada para 300,
portanto o valor de x + y é 0 + 300. Portanto, o valor da
chamada soma_yy(z) é 300, e este número será impresso pelo
terceiro cout em main().
Portanto, a saída da execução deste programa será
100
300
300
Neste exemplo, o escopo da variável global y é o programa todo.
O escopo da variável local z, definida dentro de maio é o
corpo da função main. O escopo do parâmetro formal x da
função soma_y é o corpo de soma_y. O escopo do parâmetro
formal x da função soma_yy é o corpo de soma_yy.
Aqui apresentamos um exemplo de uma função mais complicada. Esta função calcula a ``raiz quadrada inteira'' de um número (o maior inteiro menor ou igual a raiz quadrada do número).
Este programa usa o algoritmo ``divide e calcula média'' (uma aplicação do método de Newton). Ele executa o seguinte:
Dado ![]() , achar
, achar ![]() computando sucessivamente
computando sucessivamente
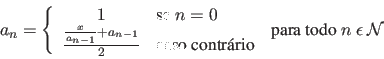
Os valores de ![]() convergem para
convergem para ![]() a medida que
a medida que ![]() cresce.
cresce.
Para achar a raiz quadrada inteira, este algoritmo é repetido até que
Por exemplo, para achar a raiz quadrada inteira de ![]() (usando divisão
inteira que trunca a parte fracional do número)
(usando divisão
inteira que trunca a parte fracional do número)
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
Uma vez que
![]() , o processo termina e a resposta é
, o processo termina e a resposta é ![]() .
.
(Não é necessário você entender por que este algoritmo funciona - portanto não se preocupe se não conseguir entendê-lo)
int raizInteira(int); /* prototipo */ /************************************************************** * function: raizInteira(x) * acao: dado x, retorna a raiz quadrada inteira de x * in: inteiro positivo x * out: raiz quadrada inteira de x * suposicoes: x >= 0 * algoritmo: metodo de dividr e calcular media: comecando com * um palpite de 1, o proximo palpite e' calculado como * (x/palpite_ant + palpite_ant)/2. Isso e' repetido * ate' que palpite^2 <= x < (palpite+1)^2 ***************************************************************/ int raizInteira(int x) { int palpite = 1; /* Continue ate' que o palpite esteja correto */ while (!(x >= palpite*palpite && x < (palpite+1)*(palpite+1))) { /* Calcula proximo palpite */ palpite = (x/palpite + palpite) / 2; } return palpite; }
Note que usando a lei de DeMorgan, podemos re-escrever a expressão teste do while em uma forma equivalente:
x < palpite * palpite || x >= (palpite + 1) * (palpite + 1)
Deve estar claro neste ponto a diferenca entre ação e algoritmo. Uma pessoa que quer usar esta função precisa saber somente a ação, não o algoritmo. É também importante especificar os dados que são esperados pela função e retornados por ela para outras pessoas poderem usá-la. As suposições devem esclarecer as restrições da função sobre quando a função pode falhar ou produzir resultados errados. Neste caso, um número negativo produziria um erro, já que números negativos não possuem raiz quadrada.
Não há necessidade de ir em muitos detalhes em qualquer parte da documentação da função. Embora ela deva conter informação suficiente para que alguém (que não possa ver o código) saber utilizá-la. Detalhes sobre implementação e detalhes menores sobre o algoritmo devem ser colocados como comentários no próprio código.
Definições de funções em C++ não podem ser aninhadas, mas ativações de função podem: uma função, digamos A, pode chamar uma outra função, digamos B (dizemos que A chama B). Nos referimos a A como o ``chamador'' e B como a função ``chamada''.
O que acontece quando uma função chama outra (quando A chama B)? Um registro especial, chamado registro de ativação é criado. A informação neste registro é necessária para a ativação da função chamada e para a reativação do chamador depois que a execução da função chamada termina.
O fluxo de controle através de ativação de funções é da forma último-que-entra-primeiro-que-sai. Se A chama B e B chama C: A é ativado primeiro, então B é ativado (um registro de ativação para ``A chama B'' é criado e armazenado, A é temporariamente suspenso), então C é ativado (um registro de ativação de ``B chama C'' é criado e armazenado, A e B são suspensos); C é o último a iniciar execução, mas o primeiro a terminar (último-a-entrar-primeiro-a-sair). Depois que C termina, B é reativado. O registro de ativação ``B chama C'' foi criado por último, mas o primeiro a ser destruído (no momento que o controle é retornada para B). Depois que B termina, A é reativado. O registro de ativação correspondente a ``A chama B'' é destruído no momento em que o controle retorna para A.
Nas notas de aula anteriores, enfatizamos arrays de números. Em geral, podemos ter arrays com elementos de qualquer um dos tipos vistos até agora (incluindo arrays - visto nas notas de aula 9). Nesta seção, apresentaremos arrays com elementos do tipo char, usados para representar textos em programas.
Abaixo, apresentamos um exemplo de programa que define e inicializa um array de caracteres, e depois imprime o array em ordem reversa.
#include <iostream>
using namespace std;
int main()
{
char arr1[] = {'c','i','2','0','8'};
int i;
for (i = 4; i >= 0; i -= 1)
cout << arr1[i];
}
Arrays de caracteres são usados para armazenar texto, mas é
muito inconveniente se tivermos que colocar cada caractere entre
apóstrofes. A alternativa dada pela linguagem C++ é
char arr2[] = "ci208" ;Neste caso, ``ci208'' é um string de caracteres ou uma constante do tipo string. Nós já usamos strings antes, com as funções cout (constantes do tipo string estão sempre entre aspas -
"):
cout << "Entre com a nota para o estudante 2: "; cin >> gr2;
Strings são essencialmente arrays de caracteres (arrays com
elementos do tipo char) que DEVEM terminar com '\0'.
Normalmente é conveniente definir a constante NULO em seu programa para
representar este terminador: #define NULO '\0'.
No exemplo acima, embora não tenhamos escrito explicitamente o caracter NULO, o compilador automaticamente o colocou como o último elemento do array arr2[]. Portanto, o tamanho de arr2[] é 6: 5 para os caracteres que indicamos (ci208) e 1 para o caractere NULO que o compilador introduziu automaticamente. As definições abaixo são equivalentes.
char arr2[] = {'c','i',' ', '2','0','8','\0'};
char arr2[] = {'c','i',' ', '2','0','8', NULO};
O caractere NULO marca o final de um string.
Outros exemplos:
// a maneira tediosa
char name1[] = { 'j','o','s','e',' ','s','i','l','v','a','\0' };
// e a maneira facil
char name2[] = "jose silva";
Embora o primeiro exemplo seja um string, o segundo exemplo mostra
como strings são geralmente escritos (como constantes). Note que se
você usar aspas quando escreve uma constante, você não precisa
colocar '\0', porque o compilador faz isso para você.
Quando você for criar um array de caracteres de um tamanho específico, lembre-se de adicionar 1 para o tamanho máximo de caracteres esperado para armazenar o caractere NULO. Por exemplo, para armazenar o string ``programar eh divertido'', você precisa de um array de tamanho 22 (21 caracteres + 1 para o NULO).
Strings podem ser impressos usando cout . Por exemplo:
int main()
{
char mensagem[] = "tchau";
cout << "ola" << endl << mensagem << endl;
}
A saída deste programa é:
ola
tchau
A função cin.getline() lê uma linha de texto digitado no teclado e a armazena em um vetor indicado como primeiro argumento. O segundo argumento da função indica o número máximo de caracteres que será lido. Veja o exemplo abaixo:
#include <iostream> using namespace std; int main() { char nome[100]; cout << "Entre seu nome: "; cin.getline (nome, 100); cout << "Oi, " << nome << "." << endl ; }
Exemplo de execução
Entre seu nome: Jose Silva Oi, Jose Silva.
Passando um nome de array para a função cin.getline(), como ilustrado no programa acima, coloca a linha inteira digitada pelo usuário no array nome (tudo ou máximo de 99 caracteres até que seja teclado enter). Note que se o usuário digitar caracteres demais (neste caso, mais de 99 caracteres), apenas os primeiros 99 caracteres digitados serão copiados para o array indicado no primeiro argumento da função.
A função cin pode ser usada de maneira similar. A única diferença é que cin lê somente a primeira palavra (tudo até que se digite um separador - um espaço em branco, tabulação, ou enter).
#include <iostream> using namespace std; int main() { char nome[100]; cout << "Entre seu nome: "; cin >> nome; cout << "Oi, " << nome << "." << endl; }
Exemplo de execução
Entre seu nome: Jose Silva Oi, Jose.
Note que somente o primeiro nome é lido pelo cin porque a função pára no primeiro espaço em branco que encontra (enquanto cin.getline() pára quando encontra um enter).
#include <iostream> using namespace std; #define NUM_NOMES 5 // define a quantidade de nomes no array #define TAM 20 // define o tamanho maximo do nome int main() { char nomes[NUM_NOMES][TAM] = {"Jose Silva", "Maria Silva", "Antonio dos Santos", "Pedro dos Santos", "Joao da Silva"}; int i; for(i = 0; i < 5; i++) cout << nomes[i] << endl; }
A saída deste programa é:
Jose Silva Maria Silva Antonio dos Santos Pedro dos Santos Joao da Silva
Há funções para manipulação de string já definidas na biblioteca padrão C++ chamada cstring. Todas as funções que apresentaremos nesta seção são parte desta biblioteca. Portanto, se seu programa utilizar uma destas funções você deve incluir a linha #include <cstring> no início do seu programa.
O objetivo desta seção é mostrar como estas funções poderiam ser implementadas como exemplos de programas de manipulação de strings.
A função strlen() tem como argumento um string. Ela retorna um inteiro que é o comprimento do string (o número de caracteres do string, não contando o caractere NULL). Por exemplo, o comprimento do string ``alo'' é 3.
#include <iostream> #include <cstring> using namespace std; int main() { char nome[100]; int comprimento; cout << "Entre seu nome: "; cin.getline(nome, 100); comprimento = strlen(nome); cout << "Seu nome tem " << comprimento << " caracteres." << endl; }
Um exemplo de execução:
Entre seu nome: Dostoevsky Seu nome tem 10 caracteres.
Abaixo, mostramos como a função strlen() poderia ser implementada.
int strlen( char str[] )
{
int comprimento = 0;
while ( str[comprimento] != NULL )
++comprimento;
return comprimento;
}
A função strcmp() é usada para comparar dois strings. Lembre que não podemos usar ==, como em str1 == str2, para comparar dois strings, uma vez que strings são arrays. Strings devem ser comparados caractere por caractere. A função strcmp() tem como argumento dois strings e retorna um inteiro.
Strings são ordenados de forma similar a maneira como palavras são ordenadas em um dicionário. Ordenamos palavras em um dicionário alfabeticamente, e ordenamos strings respeitando a ordem dos caracteres no conjunto de caracteres da máquina. A ordenação abaixo é válida em qualquer computador:
'0' < '1' < ... < '8' < '9' 'A' < 'B' < ... < 'Y' < 'Z' 'a' < 'b' < ... < 'y' < 'z'A ordem relativa do três conjuntos (dígitos, letras maiúsculas e letras minúsculas) depende do computador utilizado.
Se s1 e s2 são strings, o resultado da chamada de função strcmp(s1, s2) é:
![]() se s1
se s1 ![]() s2, strcmp() retorna 0
s2, strcmp() retorna 0
![]() se s1
se s1 ![]() s2, strcmp() retorna
um número negativo (< 0)
s2, strcmp() retorna
um número negativo (< 0)
![]() se s1
se s1 ![]() s2, strcmp() retorna
um inteiro positivo (> 0)
s2, strcmp() retorna
um inteiro positivo (> 0)
(onde ![]() ,
, ![]() e
e ![]() são
são ![]() ,
, ![]() e
e ![]() para strings)
para strings)
![]() significa ``
significa ``![]() vem antes de
vem antes de ![]() no dicionário''.
Exemplos:
``tudo'' é menor que ``xadrez'', ``calor'' é menor que
``calorao'', ``frio'' é menor que ``quente'', e é claro o
string vazio , NULL, é menor que qualquer string.
no dicionário''.
Exemplos:
``tudo'' é menor que ``xadrez'', ``calor'' é menor que
``calorao'', ``frio'' é menor que ``quente'', e é claro o
string vazio , NULL, é menor que qualquer string.
Considere o exemplo abaixo que usa strcmp():
#include <iostream> #include <cstring> using namespace std; int main() { char palavra1[100], palavra2[100]; int resultado; cout << "entre com uma palavra: "; cin >> palavra1; cout << "entre outra palavra: "; cin >> palavra2; resultado = strcmp(palavra1, palavra2); if (resultado == 0) cout << "igual" << endl; else if (resultado > 0) cout << "o primeiro e' maior" << endl; else cout << "o segundo e' maior" << endl; }
Aqui está um exemplo de como a função strcmp() poderia ser implementada.
int strcmp( char s1[], char s2[] )
{
int i = 0;
while (1)
{
if (s1[i] == NULL && s2[i] == NULL)
return 0;
else if (s1[i] == NULL)
return -1;
else if (s2[i] == NULL)
return 1;
else if (s1[i] < s2[i])
return -1;
else if (s1[i] > s2[i])
return 1;
else
++i;
}
}
Na biblioteca padrão, a função strcmp() faz distinção entre letras maiúsculas e minúsculas. Se você não quer que a função faça esta distinção, você pode modificar o seu string para ter apenas letras minúsculas (ou maiúsculas) antes de passá-lo como argumento para a função strcmp(). Para fazer isso, você pode usar a função da biblioteca padrão tolower(), que tem como argumento um caractere. Se o caractere passado é uma letra maiúscula, ele retorna esta letra minúscula; caso contrário, retorna o mesmo caractere. Por exemplo: tolower('A') é 'a', tolower('1') é '1', tolower('a') é 'a'.
A função strcpy() é usada para copiar o conteúdo de um string para outro. Ela tem dois argumentos: strcpy(s1, s2) copia o conteúdo do string s2 para o string s1. A função strcpy() que apresentamos abaixo não retorna um valor. Seu protótipo é
void strcmp(char [], char []);
O exemplo abaixo mostra a utilização do strcpy().
#include <iostream> #include <cstring> using namespace std; int main() { char pal[100], palCopia[100]; cout << "entre com uma palavra: "; cin >> pal; strcpy(palCopia, pal); cout << "entre outra palavra: "; cin >> pal; cout << "voce entrou primeiro: " << palCopia << endl; }
Embora este programa pudesse ter sido escrito sem usar strcpy(), o objetivo é mostrar que se pode usar strcpy() para fazer ``atribuição'' de strings.
A função strcpy() poderia ter sido implementada da seguinte forma:
void strcpy( char s1[], char s2[] )
{
int i = 0;
while ( s2[i] != NULL )
{
s1[i] = s2[i];
++i;
}
s1[i] = s2[i];
}
Em C++ é possível uma forma alternativa de lidar com textos, usando a classe String.
A estrutura de dados array é usada para conter dados do mesmo tipo junto. Dados de tipos diferentes também podem ser agregados em tipos chamados de estruturas ou registros (tipo struct em linguagem C). Primeiro, o tipo estrutura é declarado (precisamos especificar que tipos de variáveis serão combinados na estrutura), e então variáveis deste novo tipo podem ser definidas (de maneira similar que usamos para definir variáveis do tipo int ou char).
Uma declaração de estrutura declara um tipo struct. Cada tipo struct recebe um nome (ou tag). Refere-se àquele tipo pelo nome precedido pela palavra struct. Cada unidade de dados na estrutura é chamada membro e possui um nome de membro. Os membros de uma estrutura podem ser de qualquer tipo. Declarações de estrutura não são definições. Não é alocada memória, simplesmente é introduzida um novo tipo de estrutura.
Geralmente declarações de estruturas são globais. Elas são colocadas próximas ao topo do arquivo com o código fonte do programa, assim elas são visíveis por todas as funções (embora isto dependa de como a estrutura está sendo usada).
A forma padrão de declaração de uma estrutura é:
struct nome-estrutura {
declaração dos membros
} definição de variáveis (optional);
Abaixo se apresenta um exemplo de um tipo estrutura que contém um membro do tipo int e um outro membro do tipo char.
struct facil {
int num;
char ch;
};
Esta declaracao cria um novo tipo chamado struct facil que contém um inteiro chamado num e um caracter chamado ch.
Como acontece com qualquer outro tipo de dados, variáveis de tipos de estruturas são definidas fornecendo o nome do tipo e o nome da variável. Considere a definição abaixo relativa a uma variável com o nome fac1 que é do tipo struct facil:
struct facil fac1;
Tal definição está associada com a alocação de memória: memória suficiente será alocada para guardar um int e um char (nesta ordem). Como qualquer outra variável, fac1 tem um nome, um tipo, e um endereço associados.
Variáveis de estruturas possuem também valores, e como outras variáveis locais, se elas não tem atribuídas um valor específico, seu valor é indefinido.
É possível definir variáveis durente a declaração do tipo estrutura:
struct facil {
int num;
char ch;
} fac1;
Note-se que sem conflito, nomes de membros (tais como num e ch) podem ser usados como nomes de outras variáveis independentes (fora do tipo estrutura definido) or como nomes de membros em outros tipos estrutura. No entanto, deve-se evitar situações que criem confusão.
Dada uma variável de estrutura, um membro específico é referenciado usando o nome da variável seguida de . (ponto) e pelo nome do membro da estrutura. Assim, as seguintes referências a membros de uma estrutura são válidas:
fac1.num se refere ao membro com nome num na estrutura fac1;
fac1.ch se refere ao membro com nome ch na estrutura fac1.
Membros de estrutura (como fac1.num) são variáveis, e podem ser usadas como valores (no lado direito de uma atribuição, em expressões como argumentos para funções), ou como lvalues (no lado esquerdo de atribuições, com operadores de incremento/decremento ou com o operador de endereço (&)). O exemplo abaixo mostra alguns exemplos do uso de membros de estrutura:
fac1.ch = 'G';
fac1.num = 42;
fac1.num++;
if (fac1.ch == 'H') {
cout << fac1.num << endl;
}
Tentar acessar um nome de membro que não existe causa um erro de compilação.
Uma variável de estrutura pode ser tratada como um objeto simples no todo, com um valor específico associado a ela (a estrutura fac1 tem um valor que agrega valores de todos os seus membros). Note a diferença com arrays: se arr[] é um array de tamanho 2 definedo como int arr[2] = {0,1};, o nome arr2 não se refere ao valor coletivo de todos os elementos do array. Na verdade, arr2 é um apontador constante e se refere ao endereço de memória onde o array se inicia. Além disso arr2 não é um lvalue e não pode ser mudado. Variáveis de estrutura são diferentes. Elas podem ser usadas como valores e lvalues, mas com certas limitações.
Os únicos usos válidos de uma variável de estrutura são dos dois lados de um operador de atribuição (=), como operando do operador de endereço & (obtendo o endereço da estrutura), e referenciando seus membros.
De todas as variações de atribuição (incluindo o incremento e decremento) atribuição de estruturas pode ser usada APENAS com =. O uso de outros operadores de atribuição ou de incremento causará um erro de compilação A atribuição de um valor de estrutura para outro copia todos os membros de uma estrutura para outra. Mesmo que um dos membros seja um array ou outra estrutura, ela é copiada integralmente. As duas estruturas envolvidas na atribuição devem ser do mesto tipo struct. Considere o seguinte exemplo:
struct facil {
int num;
char ch;
};
void main(void)
{
struct facil fac1, fac2;
fac1.num = 3;
fac1.ch = 'C';
/* Atribuindo fac1 a fac2 */
fac2 = fac1;
}
Lembre-se que este tipo de atribuição é ilegal com arrays. Tentar fazer isto com dois arrays causa um erro de compilação (uma vez que nomes de arrays são apontadores constantes).
int a[5], b[5];
/* Está errado -- Não irá compilar */
a = b;
Variáveis de estruturas não-inicializadas contém valores indefinidos em cada um de seus membros. Como em outras variáveis, variáveis de estruturas podem ser inicializadas ao serem declaradas. Esta inicialização é análoga ao que é feito no caso de arrays. O exemplo abaixo ilustra a inicialização de estruturas:
struct facil {
int num;
char ch;
};
void main(void)
{
struct facil fac1 = { 3, 'C' }, fac2;
fac2 = fac1;
}
Uma lista de valores separados por vírgula fica entre chaves ({ e }). Os valores de inicialização devem estar na mesma ordem dos membros na declaração da estrutura.
Como qualquer outro valor do tipo int ou float, valores de estruturas podem ser passados como argumentos para funções, e podem ser retornados de funções. O exemplo abaixo ilustra tal prorpiedade:
#include <iostream> using namespace std; #define LEN 50 struct endereco { char rua[LEN]; char cidade_estado_cep[LEN]; }; struct endereco obtem_endereco(void); void imprime_endereco(struct endereco); struct endereco obtem_endereco(void) { struct endereco ender; cout << "\t Entre rua: "; cin.getline(ender.rua, LEN); cout << "\t Entre cidade/estado/cep: "; cin.getline(ender.cidade_estado_cep, LEN); return ender; } void imprime_endereco(struct endereco ender) { cout << "\t " << ender.rua << endl; cout << "\t " << ender.cidade_estado_cep << endl; } main() { struct endereco residencia; cout << "Entre seu endereco residencial:\n"; residencia = obtem_endereco(); cout << "\nSeu endereco eh:\n"; imprime_endereco(residencia); }
No exemplo acima, a estrutura struct endereco contém dois arrays de tamanho 50. Dentro da função obtem_endereco(), a variável ender é declarada como sendo do tipo struct endereco. Após usar cin.getline() para o fornecimento da informação, o valor de ender é retornado para main(), de onde a função obtem_endereco() foi chamada. Este valor é então passado para a função imprime_endereco(), onde o valor de cada membro da estrutura é exibido na tela.
Este programa pode ser comparado ao programa abaixo, que usa valores do tipo int no lugar de valores do tipo struct endereco (claro que a informação lida e exibida é um simples valor numérico, e não um nome de rua, etc.):
int obtem_int(void);
void imprime_int(int);
int obtem_int(void)
{
int i;
cout << "Entre valor: ";
cin >> i;
return i;
}
void imprime_int(int i)
{
cout << i << endl;
}
void main(void)
{
int valor;
valor = obtem_int();
cout << "\nSeu valor:\n";
imprime_int(valor);
}
Arrays de estruturas são como arrays de qualquer outro tipo. Eles são referenciados e definidos da mesma forma. O exemplo abaixo é análogo ao exemplo de endereço apresentado anteriormente, exceto que uma quantidade de NUM endereços é armazenada ao invés de apenas um.
#define LEN 50
#define NUM 10
struct endereco {
char rua[LEN];
char cidade_estado_cep[LEN];
};
void obtem_endereco(struct endereco [], int);
void imprime_endereco(struct endereco);
void obtem_endereco(struct endereco aender [], int index)
{
cout << "Entre rua: ";
cin.getline(aender[index].rua, LEN);
cout << "Entre cidade/estado/cep: ";
cin.getline(aender[index].cidade_estado_cep, LEN);
}
void imprime_endereco(struct endereco ender)
{
cout << ender.rua << endl;
cout << ender.cidade_estado_cep << endl;;
}
void main(void)
{
struct endereco residencias[NUM];
int i;
for (i = 0; i < NUM; i++) {
cout << "Entre o endereco da pessoa " << i << ":\n";
obtem_endereco(residencias,i);
}
for (i = 0; i < NUM; i++) {
cout << "endereco da pessoa " << i << ":\n";
imprime_endereco(residencias[i]);
}
}
Neste programa, o array residencias é passado para obtem_endereco(), juntamente com o indice onde deve ser guardado o novo endereço. Depois, cada elemento do array é passado para imprime_endereco() um por vez.
Observe-se ainda na função obtem_endereco() como os membros de cada elemento do array podem ser acessados. elements da estrutura em can be accessed as well. Por exemplo, para acessar a rua do elemento residencias[0] usa-se:
cout << residencias[0].rua << endl;
cout << residencias[0].cidade_estado_cep << endl;
Como definido anteriormente, membros de estruturas podem ser de qualquer tipo. Isto inclui outras estruturas. Abaixo define-se duas estruturas, a segunda tendo membros que são também estruturas:
#define LEN 50
struct endereco {
char rua[LEN];
char cidade_estado_cep[LEN];
};
struct student {
char id[10];
int idade;
struct endereco casa;
struct endereco escola;
};
struct student pessoa;
Dadas estas definições, pode-se potencialmente acessar os seguintes campos de pessoa, uma variável do tipo struct student:
pessoa.id
pessoa.casa.rua
pessoa.casa.cidade_estado_cep
pessoa.escola.rua
pessoa.escola.cidade_estado_cep
Note o uso repetido de . quando se acessa membros dentro de membros.
A forma com que um programa em C++ se comunica com o mundo externo é através de entrada e saída de dados: o usuário fornece dados via teclado e o programa imprime mensagens na tela. Todos os programas vistos até agora lêem suas entradas do teclado e produzem suas saídas na tela.
Em C++ toda entrada e saída é feita com fluxos (streams) de caracteres organizados em linhas. Cada linha consiste de zero ou mais caracteres e termina com o caracter de final de linha. Pode haver até 254 caracteres em uma linha (incluindo o caracter de final de linha). Quando um programa inicia, o sistema operacional automaticamente define quem é a entrada padrão (geralmente o teclado) e quem é a saída padrão (geralmente a tela).
As facilidades de entrada e saída não fazem parte da linguagem C++ . O que existe é uma biblioteca padrão de classes e funções (métodos) para manipular a transferência de dados entre programa e os dispositivos (devices) de saída e entrada padrão: cin, cout, cin.get(), cin.put(), puts(), gets(). Estas classes e funções são declaradas no arquivo <iostream>. Existem funções úteis para conversão e teste de caracteres declaradas no arquivo <ctype.h>.
As funções de entrada e saída operam sobre streams (fluxos) de caracteres. Toda vez que uma função se entrada é chamada (por exemplo, cin, cin.get()) ela verifica pela próxima entrada disponível na entrada padrão (por exemplo, texto digitado no teclado). Cada vez que uma função de saída é chamada, ela entrega o dado para a saída padrão (por exemplo, a tela).
As funções para leitura da entrada padrão e para escrita na saída padrão que têm sido usadas até agora são:
int cin.get( void ); int cin.put( int );
char *gets(char *); int puts( char *);
int cin >> arg1 >> arg2 >> ...; int cout << arg1 << arg2 << ...;
Vamos discutir algumas funções de entrada de dados (diferente do
cin). A entrada de texto é considerada como um fluxo de
caratecteres. Um fluxo texto é uma sequência de caracteres
dividida em linhas; cada linha consiste de zero ou mais caracteres
seguido do caractere de nova linha ( \n). Como
programador, você não quer se preocupar em como as linhas são
representadas fora do programa. Quem faz isso por você são funções de
uma biblioteca padrão.
Suponha que você queira ler um único caractere, sem fazer qualquer tipo de conversão para um tipo de dados específico (o que é feito por cin). Isso pode ser feito usando a função cin.get().
A função cin.get() lê o caracter do teclado e mostra o que foi digitado na tela.
#include <iostream>
using namespace std;
int main()
{
char ch;
cout << "Digite algum caracter: ";
ch = cin.get();
cout << "\n A tecla pressionada eh " << ch << endl;
}
O Resultado deste programa na tela é:
Digite algum caracter: A
A tecla pressionada eh A.
A função cin.put() aceita um argumento de entrada, cujo valor será impresso como caracter:
#include <iostream>
using namespace std;
int main()
{
char ch;
cout << "Digite algum caracter: ";
ch = cin.get();
cin.put(ch);
}
cin.get() é uma função vinculada à primitiva principal de entrada
cin. Cada vez que é chamada, esta função lê um caractere
teclado; cin.get começa a ler depois que a tecla ![]() é
digitada no final de uma sequência de caracteres (dizemos que a entrada
para a função cin.get() está no fluxo de entrada). A função
cin.get() retorna um valor, o caractere lido (mais precisamente,
o código inteiro ASCII correspondente ao caractere).
é
digitada no final de uma sequência de caracteres (dizemos que a entrada
para a função cin.get() está no fluxo de entrada). A função
cin.get() retorna um valor, o caractere lido (mais precisamente,
o código inteiro ASCII correspondente ao caractere).
Vejamos o que acontece quando um programa trivial é executado.
#include <iostream>
using namespace std;
int main(){
char ch;
ch = cin.get();
}
cin.get() obtém sua entrada do teclado. Portanto, quando o
programa acima é executado, o programa espera que o usuário digite
alguma coisa. Cada caractere digitado é mostrado no monitor. O
usuário pode digitar diversos caracteres na mesma linha, inclusive backspace para corrigir caracteres já digitados. No momento que ele
teclar ![]() , o primeiro caractere da sequência digitada é o
resultado da função cin.get(). Portanto, na
instrução do programa acima o caractere (ou melhor, o seu
código ASCII) é atribuído a variável ch.
Note que o usuário pode ter digitado diversos caracteres antes de
teclar
, o primeiro caractere da sequência digitada é o
resultado da função cin.get(). Portanto, na
instrução do programa acima o caractere (ou melhor, o seu
código ASCII) é atribuído a variável ch.
Note que o usuário pode ter digitado diversos caracteres antes de
teclar ![]() , mas a função cin.get() só
começará a ler o que foi digitado depois que for teclado
, mas a função cin.get() só
começará a ler o que foi digitado depois que for teclado ![]() .
Além disso, com uma chamada da função cin.get() só
o primeiro caractere da sequência digitada é lida.
.
Além disso, com uma chamada da função cin.get() só
o primeiro caractere da sequência digitada é lida.
Você deve saber que o caractere de nova linha, \n, que tem o
código ASCII 10, é automaticamente adicionado na sequência de
caracteres de entrada quando o ![]() é teclado. Isso não tem
importância quando a função cin.get() é chamada uma única
vez, mas isto pode causar problemas quando ele é usado dentro de um
laço.
é teclado. Isso não tem
importância quando a função cin.get() é chamada uma única
vez, mas isto pode causar problemas quando ele é usado dentro de um
laço.
No inicício de qualquer programa que usa cin.get(), você deve incluir
#include <iostream>
using namespace std;
Esta diretiva do pré-processador diz ao compilador para incluir informações sobre cin, cin.get() e EOF (mais sobre EOF adiante.).
Considere o seguinte programa:
#include <iostream>
using namespace std;
int main(){
char ch;
cout << "Entre com uma letra: ";
ch = cin.get();
if( ch < 'A' || ch > 'z' )
cout << "Voce nao teclou uma letra!";
else
cout << "Voce teclou " << ch
<< ", e seu codigo ASCII eh " << (int) ch << endl;
}
Um exemplo da execução do programa:
Entre com uma letra: A
Voce teclou A, e seu codigo ASCII eh 65.
No exemplo de execução acima o usuário teclou A e depois ![]() .
.
Outro exemplo de execução do programa:
Entre com uma letra: AbcD
Voce teclou A, e seu codigo ASCII eh 65.
Neste caso o usuário digitou quatro caracteres e depois teclou ![]() .
Embora quatro caracteres tenham sido digitados, somente uma chamada a
função cin.get() foi feita pelo programa, portanto só um
caractere foi lido. O valor atribuído ao argumento da função é o código
ASCII do primeiro caractere lido.
.
Embora quatro caracteres tenham sido digitados, somente uma chamada a
função cin.get() foi feita pelo programa, portanto só um
caractere foi lido. O valor atribuído ao argumento da função é o código
ASCII do primeiro caractere lido.
O tipo do resultado da função cin.get() é int e não char. O valor retornado pela função é o código ASCII do caractere lido.
Frequentemente quando você está digitando a entrada para o programa,
você quer dizer ao programa que você terminou de digitar o que queria.
Em ambiente Unix, digitando ^D (segure a tecla de
Ctrl e pressione D) você diz ao programa que terminou a
entrada do programa. Em ambiente MS-Windows, você faz isto digitando
^Z (segure a tecla de Ctrl e pressione Z).
Isto envia uma indicação para a função cin.get(). Quando isso ocorre, o valor de ch depois de executar ch = cin.get(); será um valor especial do tipo inteiro chamado EOF (que significa end of file - final do arquivo).
Considere o seguinte programa exemplo que conta o número de caracteres digitados (incluindo o caractere de ``próxima linha''):
#include <iostream>
using namespace std;
int main()
{
int total = 0;
char ch;
// Le o proximo caractere em ch e pára quando encontrar
// final do arquivo
ch = cin.get();
while( ! cin.eof() ) {
total++;
ch = cin.get();
}
cout << endl << total << " caracteres digitados" << endl;
}
Só para esclarecer: você deve teclar ![]() depois de entrar com o
comando
depois de entrar com o
comando ^D (ou ^Z no MS-Windows).
(Observação: nesta seção, espaços em branco são relevantes e
são mostrados como ![]() )
)
Quando você executa um programa, cada caractere que você digita é lido
e considerado como parte do fluxo de entrada. Por exemplo,
quando você usa cin.get(), você deve teclar ![]() no final.
Como mencionado anteriormente, o primeiro caractere digitado é lido
pelo cin.get(). Mas, o caractere de nova linha continua no fluxo
de entrada (porque você teclou
no final.
Como mencionado anteriormente, o primeiro caractere digitado é lido
pelo cin.get(). Mas, o caractere de nova linha continua no fluxo
de entrada (porque você teclou ![]() ).
).
De qualquer forma, se você executar um cin.get() depois de um cin ou de um cin.get() você lerá o caractere de nova linha deixado no fluxo de entrada.
Da mesma forma, quando você usa cin para ler informações, ele
somente lê o que é necessário. Se voce usar cin para ler um
número inteiro e digitar 42![]()
![]() (seguido de
(seguido de
![]() ), o cin lê
), o cin lê 42, mas deixa ![]()
![]() (e
o caractere de nova linha do
(e
o caractere de nova linha do ![]() ) no fluxo de entrada.
) no fluxo de entrada.
Outro caso ``problemático'' é quando o cin é usado num laço. Se você digitar um valor do tipo errado, o cin lerá o valor errado e a execução do laço continuará na sentença após o cin . Na próxima iteração do laço o cin vai tentar ler novamente, mas o ``lixo'' deixado da iteração anterior ainda estará lá, e portanto a chamada corrente do cin também não dará certo. Este comportamento resultará num laço infinito (um laço que nunca termina), ou terminará e terá um resultado errado.
Há uma maneira simples de resolver este problema; toda vez que você usar cin.get() (para ler um caracter só) ou cin , você deve ler todo o ``lixo'' restante até o caractere de nova linha. Colocando as seguinte linhas após chamadas a cin.get() ou cin o problema é eliminado:
// Pula o restante da linha
while( cin.get(c) != '\n' );
Note que isso não é necessário após todas as chamadas a cin.get() ou cin . Só depois daquelas chamadas que precedem cin.get() (ou cin ), especialmente em um laço.
Muitas vezes queremos em nossos programas que eles obtenham um certo tipo de dado do usuário (por exemplo, valores inteiros) mas queremos também tratar a condição em que o usuário digita um dado real ou texto no lugar, exigindo uma reentrada de dados.
O exemplo abaixo nos mostra como fazer isto, usando a sentença com cin como expressão de um if ou while.
#include <iostream> #include <cstdlib> #include <cmath> #include <cstring> using namespace std; void cleanInput() { char cc; if (cin.fail()) { cin.clear(); while (cin.get(cc) && cc != '\n'); } } void printStatInput() { cout << "\tGood: " << cin.good() << " Fail: " << cin.fail() << " Bad: " << cin.bad() << " EOF: " << cin.eof() << endl << endl; } int main () { int b=1111, c=2222, d=3333; float x=1.111, y=2.222; void * cinerr; cout << "b c d = " << b << " " << c << " " << d << endl; cout << "x y = " << x << " " << y << endl; while (! (cinerr = cin >> b)) { cleanInput(); cout << "cin 1 = " << cinerr << " b = " << b << endl; printStatInput(); cout << "Entrada 1: "; } cout << "** cin 1 = " << cinerr << " b = " << b << endl; while (! (cinerr = cin >> b >> c >> d)) { cleanInput(); cout << "cin 2 = " << cinerr << " b c d = " << b << " " << c << " " << d << endl; printStatInput(); cout << "Entrada 2: "; } cout << "** cin 2 = " << cinerr << " b c d = " << b << " " << c << " " << d << endl; cinerr = cin >> x; cout << "cin 3 = " << cinerr << " x = " << x << endl; printStatInput(); if (!cinerr) { /* Limpar condição de erro em cin, se houver. */ cout << "Limpando condições de erro de CIN" << endl; cin.clear(); printStatInput(); } cout << "Ultima entrada: "; cinerr = cin >> x >> y; cout << "cin 4 = " << cinerr << " x y = " << x << " " << y << endl; printStatInput(); return 0; }
cin » ... retorna um valor especial5. Se nulo, a entrada não foi aceita e o valor da variável em que houve erro fica inalterado. As variáveis posteriores na leitura em que houve erro também mantém seus valores inalterados. Execuções subsequentes de cin somente podem ser feitas após a execução de cin.clear(), para eliminar a condição de erro. Caso isto não seja feito, após o primeiro erro de leitura, todos os cin » ... subsequentes darão erro.
Também podem ocorrer problemas de conversão de tipos em cin. Observe o exemplo abaixo:
int b;
float x;
cin >> b;
cin >> x;
Neste caso, se usuário digita um float (por exemplo, 3.7) no 1º cin, o 2o.º cin não solicitará dado: 'b' recebe 3, deixando os chars '.4' no buffer de leitura. o 2º cin, então, armazena direto 0.4 em 'x', não aguardando digitação do usuário. Note que neste caso, cin » ... não acusará erro (isto é, não retorna valor nulo).
Para formatar a saída de dados com cout, (por exemplo, restringir a quantidade de casas decimais mostradas, definir o tamanho máximo em caracteres, ou imprimir uma matriz de valores alinhados adequadamente pelas colunas) usam-se a função setw() e o método setf() (cout.setf(....)).
Os exemplos abaixo mostram como usar estes elementos.
#include <iostream> #include <iomanip> // Necessário para usar os manipuladores setw() using namespace std; int main() { int n1, n2, n3; int soma; cout << "Entre com 3 numeros inteiros: "; cin >> n1 >> n2 >> n3; soma = n1 + n2 + n3; cout << "Soma = " << soma << endl; /* Define impressão de números em ponto fixo e mostra sempre o ponto decimal seguido por zeros */ cout.setf (ios::fixed | ios::showpoint); /* Outros flags válidos para setf(): ios::fixed ios:scientific ios::showpoint ios::right ios::left */ /* Define quantidade de algarismos a serem exibidos após ponto decimal. Em alguns compiladores, pode indicar a quantidade de algarismos SIGNIFICATIVOS. */ cout.precision(2); // setw() fixa a largura do campo de saída. // Aplica-se apenas ao próximo item exibido na saída. // Necessário incluir <iomanip> (vide início do código) cout << "Media = " << setw(8) << soma / 3.0 << endl; cout << "Produto = " << n1 * n2 * n3 << endl; }
// Exemplo de array 2-D - taboada #include <iostream> #include <iomanip> // Necessário para usar os manipuladores setw() using namespace std; #define LIN 10 #define COL 10 int main() { int x; // numero da coluna int y; // numero da linha int taboada[LIN][COL]; // tabela de taboada // preenche a taboada y=0; while(y < LIN) { x=0; while(x < COL) { taboada[y][x] = y*x; x = x+1; } y = y+1; } cout << "\n Taboada de Multiplicacao\n"; // Imprime o numero das colunas cout << setw(6) << 0; x=1; while(x < COL) { cout << setw(3) << x; x = x+1; } cout << endl; // Imprime uma "linha horizontal" cout << " "; x=0; while (x < 3*COL) { cout << "-"; x = x+1; } cout << endl; // Imprime as linhas da tablea. // Cada linha a precedida pelo indice de linha e uma barra vertical y=0; while (y < LIN) { cout << setw(2) << y << "|"; x=0; while(x < COL) { cout << setw(3) << taboada[y][x]; x = x+1; } cout << endl; y = y+1; }
O armazenamento de dados em variáveis e arrays é temporário. Arquivos são usados para armazenamento permanente de grandes quantidades de dados (e programas) em dispositivos de armazenamento secundário, como discos.
Ás vezes não é suficiente para um programa usar somente a entrada e saída padrão. Há casos em que um programa deve acessar arquivos. Por exemplo, se nós guardamos uma base de dados com endereços de pessoas em um arquivo, e queremos escrever um programa que permita ao usuário interativamente buscar, imprimir e mudar dados nesta base, este programa deve ser capaz de ler dados do arquivo e também gravar dados no mesmo arquivo.
No restante desta seção discutiremos como arquivos de texto são manipulados em C++ . Como será visto, tudo ocorre de maneira análoga ao que acontece com entrada e saída padrão.
C++ visualiza cada arquivo simplesmente como um fluxo (stream) seqüencial de bytes. Cada arquivo em C++ termina com um marcador de final de arquivo (end-of-file), definido pela constante EOF.
As regras para acessar um arquivo são simples. Antes que um arquivo seja lido ou gravado, ele é aberto. Um arquivo é aberto em um modo que descreve como o arquivo será usado (por exemplo, para leitura, gravação ou ambos). Um arquivo aberto pode ser processado por funções da biblioteca padrão em C++ . Estas funções são similares às funções de biblioteca que lêem e escrevem de/para entrada/saída padrão. Quando um arquivo não é mais necessário durante a execução do programa ele deve ser fechado. Ao final da execução de um programa todos os arquivos abertos são automaticamente fechados. Existe um número máximo de arquivos que podem ser simultaneamente abertosde forma que você deve fechar arquivos quando você não precisa mais deles em seu programa.
Quando um arquivo está aberto, um stream é associado ao arquivo. Este stream fornece um canal de comunicação entre um arquivo e o programa. Para definir tal stream, uma variável do tipo ofstream, ifstream ou fstream deve ser declarada. Esta variável irá ser usada para associar um arquivo em disco que tem um certo nome com as operações de leitura e gravação que veremos adiante. Três variáveis deste tipo e seus respectivos streams são abertos automaticamente quando um programa inicia sua execução: a entrada padrão (cin), a saída padrão (cout) e a saída padrão de erros (cerr).
Para abrir um arquivo, deve ser usada a função (método) open() associada à uma variável de um dos tipos stream. open() toma dois argumentos: o primeiro argumento é do tipo string e representa o nome do arquivo (por exemplo data.txt); o segundo argumento é a indicação do modo no qual o arquivo deve ser aberto. open() negocia com o sistema operacional e define o estado final do processo de abertura, que deve ser testado com o método fail()().
O programador/usuário não necessita saber detalhes de como a transferência de dados entre programa e arquivo é feita. As únicas sentenças necessárias no programa são a definição de uma variável do tipo stream e a abertura do arquivo. As sentenças abaixo dão um exemplo de como abrir o arquivo data.txt para leitura.
ifstream infile;
infile.open("data.txt");
O protótipo do método open() é:
<stream>.open(char *name);
open() recebe um argumento: uma string que é um nome de um arquivo a ser aberto. o tipo do stream indica a operação que será feita no arquivo: ofstream para escrita apenas, ifstream para leitura apenas, e fstream para leitura e escrita. Para este último tipo, o método open() recebe um segundo argumento, indicando o modo de abertura do arquivo: ios::in indica que o arquivo será aberto apenas para leitura; ios::out, para escrita apenas. Associado a estes valores podem ser usados os valores ios::app, ios::ate, ios::trunc, e ios::binary.
Se o arquivo não existe e é aberto para escrita, fopen() cria o arquivo. Se um arquivo já existente é aberto para escrita, o seu conteúdo é descartado. Há outros modos, incluindo anexação a um arquivo, leitura e escrita simultânea; para mais detalhes, veja a documentação da função nos livros-texto ou no manual on-line.
Para verificar se um arquivo é aberto com sucesso, usam-se os métodos fail() ou is_open(). Estas funções retornam o valor 1 (um) indicando respectivamente se houve falha na abertura ou se a abertura foi efetuada com sucesso. Alguns dos erros possíveis são: abrir um arquivo que não existe para leitura, abrir um arquivo para escrita quando não há mais espaço disponível em disco, ou abrir um arquivo para qualquer operação sendo que as permissões de acesso do arquivo não o permitem.
É recomendável que você teste se a abertura teve sucesso antes de continuar o programa. O trecho de programa abaixo ilustra como fazê-lo:
#include <iostream>
#include <fstream>
using namespace std;
....
fstream fp;
char fnome[13];
printf("Entre um nome de arquivo para abrir:");
cin >> fnome;
fp.open(fnome, ios::out);
if (fp.fail())
{
cout << "Erro na abertura de "<< fnome << " no modo escrita" << endl;
return ;
}
else
cout << "Arquivo " << fnome << " aberto com sucesso no modo escrita" << endl;
...
No exemplo acima se o arquivo não puder ser aberto com sucesso, uma mensagem apropriada é exibida na saída padrão e o programa termina. Caso contrário uma mensagem indicando o sucesso na abertura do arquivo é exibida e o programa continua sua execução.
Cada arquivo aberto possui seu próprio stream. Por exemplo, se um programa vai manipular dois arquivos diferentes arq1.txt e arq2.txt simultaneamente (um para leitura e outro para escrita), dois streams devem ser declarados:
fstream fp1, fp2;
fp1.open("arq1.txt", ios::in);
fp2.open("arq2.txt", ios::out);
As variáveis do tipo stream estabelecem conexão entre o programa e o arquivo aberto. A partir do momento de abertura, o nome do arquivo é irrelevante para o programa. Todas as funções que operam sobre o arquivo usam o stream associado.
Terminada a manipulação do arquivo o programa deve fechar o arquivo. O método close() é usado com este propósito. Ela quebra a conexão entre o stream e o arquivo. O protótipo do método close() é:
<stream>.close();Abaixo um exemplo de uso de fclose():
fstream fp1, fp2;
fp1.open("arq1.txt", ios::in);
fp2.open("arq2.txt", ios::out);
..........
fp1.close();
fp2.close();
Arquivos podem guardar duas categorias básicas de dados: texto (caracteres codificados em ASCII ou UTF) ou binário (como dados armazenados em memória ou dados que representam uma imagem JPEG ou PNG).
Depois que um arquivo de texto é aberto, existem 3 formas diferentes de
ler ou escrever sequencialmente os dados: (i) um caracter por vez,
usando as funções da biblioteca padrão get() e put(); (ii)
uma linha (string) por vez, usando gets() e
puts(); e (iii) em um formato específico, usando os operadores
![]() () e
() e ![]() (), como já fizemos com cout() e
cin().
(), como já fizemos com cout() e
cin().
Os protótipos de get() e put() are
<stream>.get(); <stream>.putc(char ch);
get() retorna o próximo caracter lido do arquivo representado pela stream, ou EOF se ocorrer final de arquivo ou um erro de leitura.
put() grava o caracter ch no arquivo representado pela stream. Esta função retorna o caracter gravado ou EOF.
Abaixo segue um exemplo de programa que lê um arquivo caracter a caracter e imprime o que foi lido na saída padrão (a tela do computador):
/************************************************************************
* Lê um caracter por vez de um arquivo e
* o imprime na saída padrão
************************************************************************/
#include <iostream> /* para funções padrão de E/S */
#include <fstream> /* para funções de E/S em arquivos */
using namespace std;
int main()
{
ifstream fp;
char fnome[13];
char ch;
/* dialogo com usuário */
cout << "Entre um nome de arquivo: ";
cin >> fnome;
fp.open( fnome, ios::in ); /* abre arquivo*/
if (fp.fail()) {
printf("Erro ao abrir %s\n", fnome);
return;
}
else {
printf("Arquivo aberto com sucesso.\n");
/* Lê o arquivo caracter a caracter e imprime em stdout (saída padrão) */
while( (ch = fp.get()) != EOF )
cout << ch;
fp.close(); /* fecha arquivo */
}
}
Observe o tipo da variável ch. Mude o tipo para int e execute novamente o programa (após compilação). Você pode exlicar a diferença nos resultados?